
Introduction
Context-aware Neural MT uses context information to perform document-level translation or domain adaptation. The context of surrounding sentences allows the model to capture discourse phenomena. The context of similar sentences can also be useful to dynamically adapt the translation to a domain. In this post, we take a look at two papers which compare uni-encoder and multi-encoder Transformer architectures for context-aware Neural MT (with a focus on document-level MT).
Uni- and Dual-encoder architectures
The following figure (after Ma et al. 2020) illustrates uni-encoder and dual-encoder architectures for context-aware translation with Transformer models. 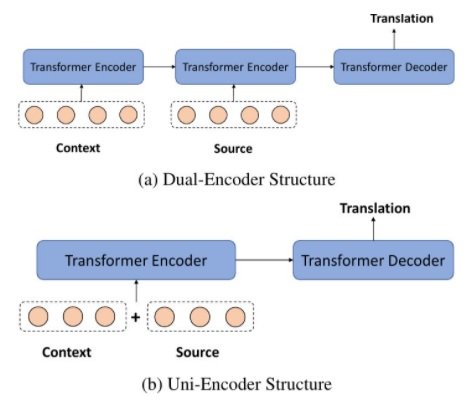
In dual-encoder Transformer models, a new encoder is added to encode the context information, and the encoder for source sentences is conditioned on this context encoder. The self-attention layers lay within each encoder and thus cannot fully capture the interaction between the contexts and the source sentences. However, in some architectures, the decoder's attention can attend to the output of both encoders. Moreover, this structure cannot be directly adapted to pre-training models, which encode multiple sentences with a single encoder.
In the uni-encoder structure, the context and source sentence representations are concatenated as the input. This structure is compatible with pre-trained models. Additionally, the attention layer can attend to both of them. However, sequences are longer, which implies a computational cost, and also dilutes the attention weights. Furthermore, the model gives equal importance to the source sentences and the context.
Do dual-encoders help?
Li et al. (2020) observe that the dual-encoder approach performs better than the standard uni-encoder approach (as described above).
They also investigate what information is captured by the context encoder. To this purpose, they compare the results with three different kinds of context: the surrounding sentences, words randomly sampled from the source vocabulary, and a fixed sentence. Surprisingly, the surrounding sentences do yield better results than the random and fixed sentences. The authors thus conjecture that the information captured by the context encoder could just introduce randomness into training, making it richer and more robust. To verify this hypothesis, they replace the context encoder output by “Gaussian noise” (a vector whose elements are sampled from a Gaussian distribution). The system with Gaussian noise outperforms the baseline (not context-aware), and gets similar scores as the system with real context. Thus it seems that the context-encoder acts more like a noise generator, which provides rich supervised training signals for robust training.
Unified Encoder
Ma et al. (2020) proposes a unified encoder architecture which addresses the problems of the standard single encoder approach, called “Flat Transformer”.
To distinguish the context sentences and the source sentences, they introduce two different representations of the sentence concatenation. Moreover, to allow a better focus on the source sentence, the encoder is split into two parts, in which the attention can respectively focus on the global level and the local level. In the bottom layers, the self-attention is applied to the whole sequence. However, at the top layers, it can only attend the positions of the source sentences. In this way, the model gives more importance to the source sentences than to the context. This is also a way to reduce the computational complexity, since long sequences only occur at the bottom layers.
Ma et al. compare the Flat Transformer to other dual- and uni-encoder architectures for document-level Neural MT. The experiments are performed on document-level datasets from TED talk transcriptions, News and Europarl (respectively 0.21, 0.24, and 1.67 million sentence pairs). The Flat Transformer achieves slightly better BLEU and METEOR scores than other approaches. With the BERT pre-trained model, these scores are further improved by 1 to 2 points. Thus, the compatibility of the unified encoder with BERT is key in this experiment.
In summary
Most approaches for context-aware Neural MT include an additional encoder to encode context information. Li et al. found that dual-encoder structures outperform the standard single encoder approach. They also observed that the gains of this additional decoder are actually because it acts as a noise generator, which provides rich supervised training signals for robust training. Thus simply adding an encoder which outputs random noise may be beneficial for training. Ma et al. address the issues with single encoders for context-aware Neural MT in a unified encoder. In this encoder, the attention attends to the concatenation of the source and context sentences in the bottom layers, and only to the source sentence in the top layers. This allows the model to clearly distinguish between the source and context sentences and lowers the computational cost. It also makes the encoder directly compatible with pre-trained models, which yields significant improvements on automated scores.
Author
Dr. Patrik Lambert
Senior Machine Translation Scientist