
Introduction
The standard way of training Neural Machine Translation (NMT) systems is by Maximum Likelihood Estimation (MLE), and although there have been experiments in the past to optimize systems directly in order to improve particular evaluation metrics, these were of limited success. Of course, using BLEU is not ideal due to the fact that it fails to account for semantic similarity, penalises similar hypothesis which differ lexically, and doesn’t assign partial credit. Attempts at training to directly maximize semantic metrics have been more successful, albeit for Statistical Machine Translation (SMT): both Lo et al. (2013) and Beloucif et al. (2014) maximised the semantic frame based metric MEANT (Lo et al. (2012)) in tuning, which resulted in improvements as measured by human judgements. This is exciting as it inches slowly closer to the way a human translator would evaluate some aspects of a translation.
In today’s blog we investigate some new work by Wieting et al. (2019) to incorporate semantic similarity into the training process for NMT, which not only improves the output, but also results in quicker convergence. They propose using their metric, SimiLe, as a reward in minimum risk training which measures the semantic similarity between the generated hypotheses and the reference translation. Based on Wieting and Gimpel (2018)’s semantic textual similarity metric, it is trained on paraphrases and evaluates via embeddings, taking the cosine similarity of two sentences, calculated as SIM. SimiLe is SIM with a length penalty, to counteract the tendency to generate overly long sentences. The fact that it was based on embeddings trained on machine-translated paraphrase pairs is a shortcoming. It is also not as principled as the previous attempts to incorporate semantics using MEANT (mentioned above), which compared semantic structures. However, hopefully more experiments will follow.
Wieting et al. (2019) base the model and optimisation procedure on work for structured prediction training by Edunov et al. (2018). The training is done with an objective function of maximum likelihood with label-smoothing, before fine-tuning the model with a weighted average of minimum risk training and label smoothing. Thus the fine-tuning objective (where the semantic component is used) is: 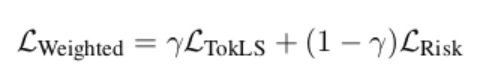 Which combines the label smoothing used by Edunov et al. (2018) with the risk loss, which is defined as:
Which combines the label smoothing used by Edunov et al. (2018) with the risk loss, which is defined as: 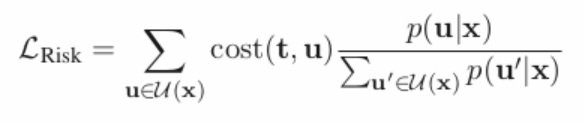 Where t is the reference, and u is a candidate hypothesis from the set of candidates. The candidates for the minimum risk training comprise 8 hypotheses from n-best lists. They train the label smoothing objective for 200 epochs, followed by 10 for the combined objective.
Where t is the reference, and u is a candidate hypothesis from the set of candidates. The candidates for the minimum risk training comprise 8 hypotheses from n-best lists. They train the label smoothing objective for 200 epochs, followed by 10 for the combined objective.
Results
They include 4 different language pairs (de-en, cs-en, ru-en, tr-en), and compare systems trained with 4 objectives:1) MLE with label smoothing,
2) minimum risk training with 1-BLEU as the cost,
3) minimum risk training with 1-SimiLe as the cost, and
4) half-SimiLe half-BLEU.
They perform automatic evaluation results using BLEU and SIM (i.e. semantic similarity alone) and show that SimiLe performs the best for all four language pairs.
They also conducted human evaluation on 200 sentences of varied system output, and found that minimum risk training with SimiLe scored highest for all languages except tr-en (where repetition seemed to be an issue). It is unclear whether judgements were made by professional translators, and whether they were judging based on source or references.
For quantitative analysis the authors focused on de-en, as the highest scoring language pair. They show that the risk objective decreases much faster, so optimising with SimiLe results in much faster training- as can be seen in the graphs below, where the top plot illustrates the expected BLEU cost and the lower plot illustrates the expected SimiLe cost when training with both BLEU and SimiLe. 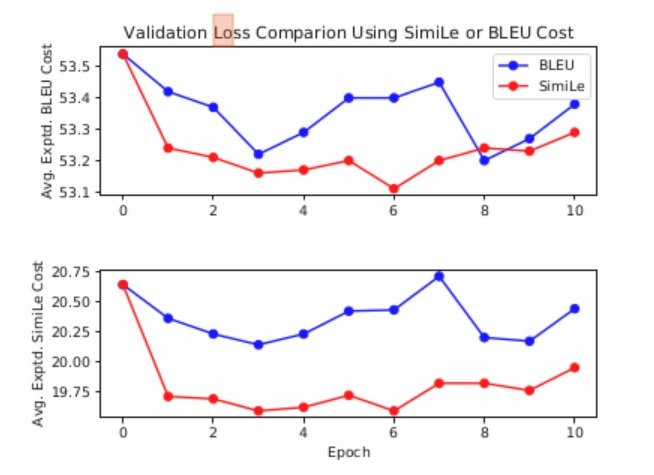 Qualitative analysis shows that SimiLe better captures the semantics of a sentence, as illustrated by this example (more in paper) where human scores are on a scale of 0-5:
Qualitative analysis shows that SimiLe better captures the semantics of a sentence, as illustrated by this example (more in paper) where human scores are on a scale of 0-5:
| SimiLe | “For me, it was very different.” | 4 |
| BLEU | “I was very different from me.” | 0 |
| MLE | “In me, it was very different.” | 1 |
| REF | “In my case, it was very varied.” |
In summary
SimiLe represents the first time a semantic similarity metric has been used as a reward in minimum risk training for NMT. It results in improvements for both automatic and human evaluation, and much higher correlation with human judgements compared to BLEU, with the bonus of faster optimization. What’s not to like?
Author
Dr. Karin Sim
Machine Translation Scientist