
Introduction
Two weeks ago, we summarised a paper alerting about worrying trends in the evaluation of MT research (issue #141). A large-scale meta evaluation revealed the prevalence of the use of BLEU score, used increasingly as the only metric despite the criticism it more and more frequently receives. The meta evaluation also showed, among other findings, that the percentage of papers performing statistical significance tests has been decreasing in the last 5 years.
This week we take a look at another paper giving solid evidence that BLEU score is not the best metric for MT system development, and that significance testing is helpful in this process. In this paper, Kocmi et al. (2021) evaluate the correlation of MT metrics with the largest collection of human judgements.
Method
Considering that in practice, MT metrics are mostly used to compare two systems, Kocmi et al. investigate which metrics have the highest accuracy to make system-level qual- ity rankings for pairs of systems, taking human judgement as a gold standard. The collection of human judgements come from manual evaluation campaigns run at Microsoft from 2018 to 2021, to compare two to four MT systems each. It includes the evaluation of 4,380 systems and 2.3 million sentences annotated by a pool of qualified professionals. This collection is publicly released with the paper. In a typical campaign, 500 sentence pairs are randomly drawn from a test set and judged using source-based Direct Assessment. The test sets are created from authentic source sentences, mostly in the news or parliamentary discussions domain. They cover 101 different languages within 232 translation directions.
The metrics included in this evaluation are metrics supporting a large number of language pairs, and thus mostly language-agnostic. Two categories are distinguished: string-based metrics and metrics using pretrained models. For all metrics, the default parameters are used.
In the pairwise comparison scenario of this evaluation, the pairs of systems are compared with the difference in metric score achieved by each system: Delta = score(system A)-score(system B). In the following figure, each point represents a difference in average human judgement (y-axis) and a difference in automatic metric (x-axis) over a pair of systems. Blue points are system pairs translating from English; green points are into English; red points are non-English systems. Spearman’s ρ correlation and Pearson’s r are indicated respectively in the top left and bottom right corners. Metrics disagree with human ranking for system pairs in pink quadrants.
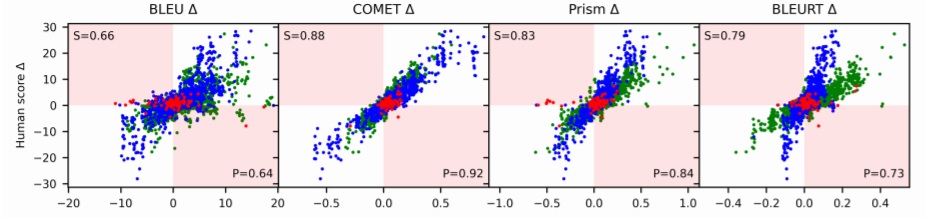
All metrics displayed in this figure exhibit a positive correlation with human judgements, but with different deviations. COMET has the smallest deviation, and thus the highest correlation with human judgements. However, comparing blue, green and red points, we can also observe that COMET, Prism, and mainly BLEURT have a different scale for different language pairs. Since we cannot assume that metrics use the same scale for different language pairs, neither Pearson’s nor Spearman’s correlation can be used in pairwise metrics evaluation. The accuracy for a given metric in ranking two systems is instead calculated as the number of times the Delta for human judgements agree with (i.e. has the same sign as) the metric Delta, divided by the total number of comparisons.
Results
Best suited metric for pairwise comparison
The metric with highest accuracy is COMET, which is therefore the most suited for ranking pairs of systems. Surprisingly, the second-best metric is COMET-src, which does not rely on a human reference. This opens possibilities to use monolingual data for effective evaluation of MT systems. The highest accuracy for string-based metrics was achieved by ChrF. Thus, according to this evaluation, ChrF is better for pairwise system comparison than BLEU (actually ranked 10th out of 12 metrics evaluated).
Non-English languages and other scenarios
For language pairs with a non-Latin script (such as Arabic, Russian) or a logogram-based (Chinese, Korean and Japanese) target language, a slight drop in metric ordering is observed for some pretrained metrics, while the ChrF score increases. Some pretrained methods may thus have issues with non-Latin scripts. This requires further investigation.
Are statistical tests on automatic metrics worth it?
The authors corroborate that statistical significance testing can largely increase the confi- dence of the MT quality improvement and increase the accuracy of metrics.
Does BLEU hijack progress in MT?
To answer this question, Kocmi et al. separately analyse two types of systems: (i) independent systems, obtained from external publicly available tools, and (ii) incremental systems, which have been submitted to human evaluation after a process of development based on BLEU score. Incremental systems with lower BLEU scores were discarded in the development phase, and the decision between the few variants with highest BLEU score was made based on human evaluation. The results for the independent systems are similar as for the global evaluation. However, for the incremental systems, BLEU score has the highest accuracy. This is because systems with BLEU score degradation, which could nevertheless have been positively judged by humans, were discarded during development. Thus the use of BLEU score could mislead many research decisions. Of course, to confirm this hypothesis, the rejected systems should be evaluated with other metrics and human judgements.
In summary
The authors suggest using a pre-trained metric as the main automatic metric for system development, and recommend COMET. They suggest using a string-based metric for unsupported languages and as a secondary metric, such as ChrF. They recommend not using BLEU. They also recommend to run a paired significance test to reduce metric misjudgement due to random sampling variation. The proof is in the pudding, and these studies show that it is definitely time to change the current default go-to practice for automatic metrics!

Author
Dr. Patrik Lambert
Senior Machine Translation Scientist