
Introduction
In recent years, there has been a lot of research in using tags (or special tokens) within neural machine translation (NMT) to pass in additional information to the model. We have covered this topic in issue #44 and #114 of our blog series and it is time to revisit this area of research. In today’s blog post, we will take a look at the work of Stergiadis et al. (2021) who propose a novel data-centric approach called Multi-Dimensional Tagging (MDT) that enables the use of a single model in the production-grade environment to support multiple subdomains by passing multidimensional sentence-level information to the model during both training and inference time.
The Approach
In the work of Caswell et al. (2019) ( issue #44), the authors propose a tagged back-translation technique that involves appending a tag at the beginning of the source-side segments during both training and inference time. The appended tag passes the meta-information to the model to distinguish between the authentic and synthetic segments in the corpus. Similar to this, in other research works (Johnson et al., 2017, Kobus et al., 2017, Sennrich et al., 2016) tagging has been used to pass different kinds of meta-information: domain, gender, language, etc.
Stergiadis et al. (2021) extend the idea of appending tags into a multi-dimensional setting; i.e. whenever multiple meaningful dimensions can be defined for the data available at training and inference time, they propose to pass in multiple tags (each representing a dimension) at the beginning of source-side sentences to encode the meta-information along each of the dimensions.
In this work, they define two different dimensions: source and domain. So, the tags representing the 2 dimensions look like:
<SYNTHETIC={0,1}>, and <DOMAIN={reviews,messaging,descriptions}>.
These tokens are used together at the beginning of each source-side segment to encode the meta-information about the domain of the sentence along with how it was generated.
Experiments and Results
Datasets:
The proposed approach is evaluated on three different translation tasks: Arabic -> English, German -> English and Russian -> English across three different domains (or subdomains of the “Travel” domain): Reviews, Messaging and Descriptions. The data statistics can be found in the table shown below :
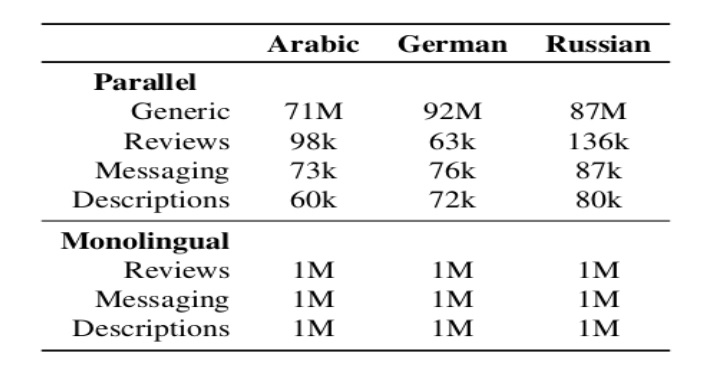
Table 1: Datasets used for the experiments
Synthetic data generation:
They generate the synthetic parallel corpus by translating the monolingual in-domain data using the model trained purely on the generic parallel corpus.
NMT Models:
The Base model - A base transformer model Vaswani et al. (2017) trained using the generic parallel corpus.
Top10 - Domain-specific models trained by fine-tuning “the base model” on the in-domain authentic and synthetic parallel corpus using the approach proposed by Edunov et al. (2018). To support three different domains, three different models are developed.
The MDT Model - This model is trained by fine-tuning “the base model” on the multi-dimensional tagged parallel corpus comprising of the data from all three different domains, each distinguished by a unique set of tags. A single model is used for all three different domain translation tasks.
Evaluation:
The authors report the results both in terms of human-evaluation scores as well as the automatic evaluation metric.
Automatic Evaluation - SacreBLEU (Post, 2018) is used to evaluate the performance of the trained models.
Human-based assessment - Professional translators rate 250 samples per language, per domain on a 4-point adequacy scale.
Results:
- From the results in table 2, it can be seen that across all the language pairs, the models trained using the MDT approach show a competitive performance (better in many cases) to the specialized models trained using the “top10” approach.
- The authors carry out an ablation experiment using the German language data to determine the significance of the insertion of tags. They fine-tune the base model using the same mix of training data but without the insertion of tags. In comparison to the MDT model, it can be inferred that without the insertion of tags, there is a significant drop in both the human evaluation and automatic evaluation results across all the domains except for the human evaluation scores of the “Descriptions” domain.
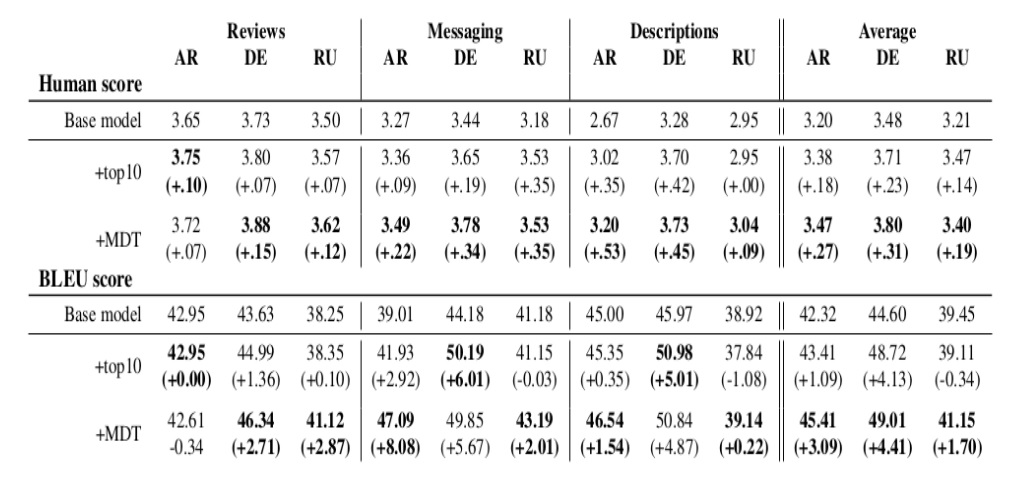
Table 2: Evaluation results as reported in the paper
In summary
Stergiadis et al. (2021) propose multi-dimensional tagging, a novel data-centric approach that can be used to simultaneously fine-tune on several sub-domains by passing multiple sentence-level tags to the model during training and inference time. Based on the evaluation results, the MDT model produces competitive results to the specialized models. Thus, this approach can be efficiently used in production-grade environments to cut down the development and maintenance cost by a factor of N, where N is the number of sub-domains involved.

Author
Akshai Ramesh
Machine Translation Scientist