

Introduction
In a previous post in our series, we examined tagged back-translation for Neural Machine Translation (NMT), whereby the back-translated data that is used to supplement parallel data is tagged before training. This led to improvements in the output over untagged data.
Today’s blog post extends the work of Caswell et al. (2019), by taking a closer look at why and how adding this unique token to the beginning of the back-translated segments helps the system differentiate between it and original source text segments in the parallel data. In particular, in the research which we are highlighting today, Marie et al. (2020) consider whether the systems trained on large amounts of back-translated data actually capture the characteristics of translationese, and whether tagging back-translations helps differentiate original texts from translations used as a source text. Translationese is the name given to the set of characteristics which differentiate a (human-) translated text from an original one. These characteristics are found to sometimes include shorter sentences and a simpler limited lexical range. They hypothesize that these characteristics are not unlike the translations generated by NMT systems. They also consider how low resource scenarios are affected by the addition of back-translated data, since one of the main areas where back-translations are used is to increment parallel data.
Experiments
They experiment with 2 language pairs: FR-EN and DE-EN, using the parallel data for the shared tasks of WMT19. For the monolingual data used for back-translation, they used extracts from the NewsCrawl corpora. For the low-resource scenario they sampled 200k sentence pairs from the parallel data which they used to train the system to back-translate sentences from the monolingual data. The test sets comprise the WMT newstest sets for en-de and en-fr which include both original and translated texts. They investigate the following scenarios:
- Test with tagged and untagged back-translations as training data
- Experiment with test sets which have source texts originally written in that language, i.e. not translated
- Test on test sets which consist of source texts which are themselves translated
- Simulate a low resource scenario and determine effect of back-translations
- Tagging test sets: tagging original sentences (as being translated ones) and decoding with a T-BT model (i.e. enforce decoding translated texts)
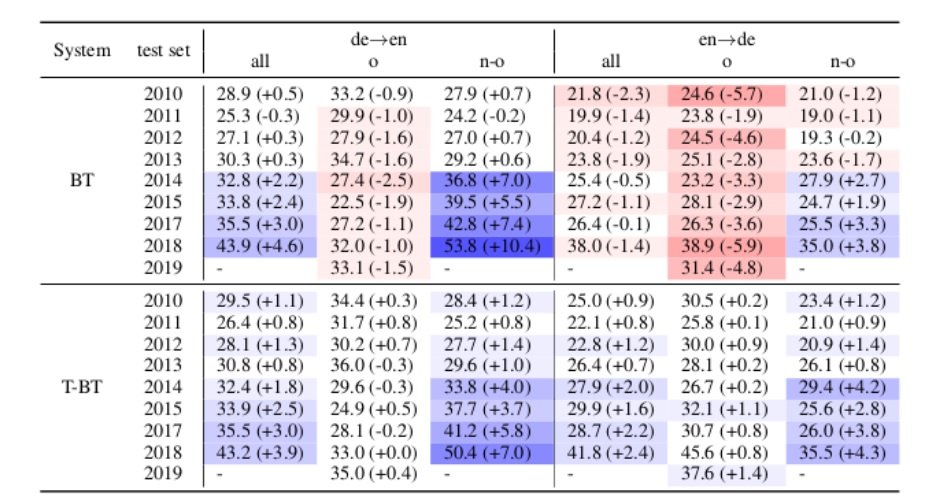
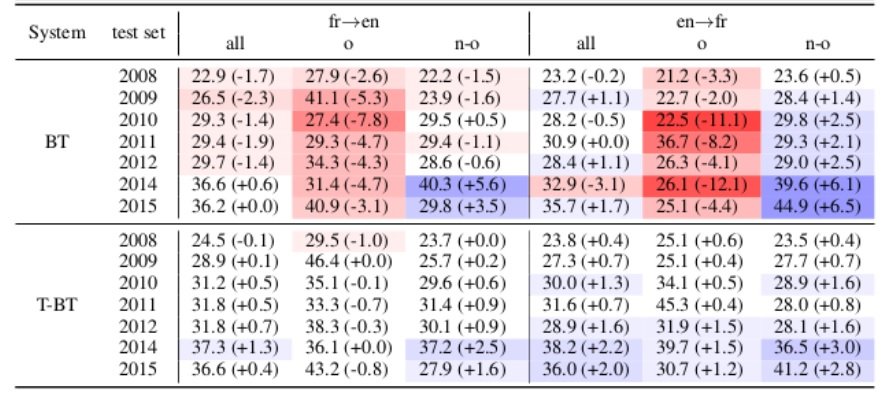 Above are the results taken from the paper, showing BLEU scores for NMT systems trained with back-translations (BT) and tagged back-translations (T-BT) for original source (o) and translations (n-o). The values in parentheses are differences over the system trained without any BT data.
Above are the results taken from the paper, showing BLEU scores for NMT systems trained with back-translations (BT) and tagged back-translations (T-BT) for original source (o) and translations (n-o). The values in parentheses are differences over the system trained without any BT data.
Results
They evaluated the system with sBLEU, using the option to specify the provenance as original text. The results indicate that when using back-translated data the scores for evaluating against original texts dropped across the board, sometimes quite significantly. Interestingly, however, the scores for evaluating against translated texts largely improved. They presume that this clearly indicates NMT overfits back-translations, due to the proportion of back translated segments.
However, tagging the back-translated segments with a unique token consistently improved the quality of output for original texts, interestingly even surpassing that of the system without the back-translated data. The tag therefore clearly helps the system identify the back-translated segments of poorer quality. The authors conclude that the tag therefore clearly helps the system identify translated texts, although given that human translations are not the same as back-translated data, what can be said is that it clearly helps identify a particular style.
Unfortunately some of the references in the WMT newstest sets considered are not of high quality, as mentioned in an earlier blog post. Moreover, while the authors state in the caption for Table 1 that they filter on the origin of the source text, this would seem to mean that in the case where the source is original (‘origlang="de" for the case of de-en experiment) then during evaluation the MT output is being compared against a reference that is actually a human translation. Conversely, when filtering for an ‘n-o’ text (i.e. where the source is regarded as a translation) then during evaluation the MT output is actually originally English (e.g. Newstest DE-EN 2018 docid="guardian.181611" genre="news" origlang="en"). Considering the example of Newstest DE-EN 2018, the reference segments where origlang=en are better quality than those translations where origlang=de. The latter is the real translation. Certainly the results make sense if n-o signifies the cases where the MT output is compared to the sometimes poorly translated segments.
For the low-resource scenario, the addition of back-translations improves the output across the board. This is unsurprising, given that back translations give necessary increase in data where there is otherwise insufficient quantities.
To further illustrate the impact the tag has, they use the tag on the testsets: tagging original segments (indicating wrongly that they are to be treated as back-translated data) and tagging translated segments, then decoding with the T-BT model . As expected, this leads to a drop in quality for the former, and an increase for the latter. This clearly proves that the tag does have the effect of enforcing a particular style. What exactly that is, is yet unclear.
In summary
In a low resource scenario, back-translation can help simply because it increases the vocabulary of the model. However, in other scenarios this is not the case, and the damage done from introducing back-translations should be mitigated by tagging those segments at training time. While back-translations can improve the output of some translated texts in high resource scenarios, this is potentially by enforcing a particular style common to some poorly translated segments in WMT newstests.Author
Dr. Karin Sim
Machine Translation Scientist