
Introduction
The enhancement of neural machine translation (NMT) models with translation memories (TMs) is an active area of research, and one which we have previously covered on this blog (issues #19 and #34). The idea is to keep exploiting the training data at inference time instead of discarding it after training. Typically, some sentence pairs are retrieved from the TM (usually the training corpus) based on the similarity between the input and the TM sentence source side. These sentence pairs are then used to adapt the translation model. This week we take a look at a paper (Cai et al., 2021) which proposes two improvements with respect to the state of the art. First, the memory only uses monolingual data in the target language instead of parallel sentence pairs. The target sentences are retrieved from the input with cross-lingual methods. Second, the cross-lingual retriever is learned during training, instead of using a static similarity-based metric. In this way, the retrieved sentences are not just the ones most similar to the input, they are the most relevant ones to improve the training objective.
Proposed Approach
The approach decomposes the translation process into two steps: retrieve, then generate. The overall framework is illustrated in the following figure.
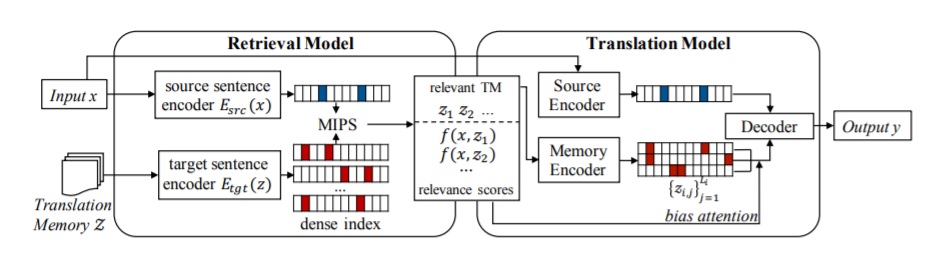
The memory Z (called “Translation Memory” in the figure, although it is not bilingual) is a set of sentences in the target language. Given the source input x, the retrieval model first selects from Z some sentences which may be helpful to translate x, according to a relevance function f. Then, the translation model generates the output conditioned on the input, the retrieved set and the relevance scores. In this way, during training, maximizing the likelihood of the translation references improves both the translation model and the retrieval model.
The retrieval model is implemented using a dual-encoder framework. The input sentence and memory sentences are both encoded with their respective encoder. The relevance score between the input sentence and a memory sentence is defined as the dot product of their vector representations. The retrieval step can be performed very efficiently.
The translation model extends the standard encoder-decoder NMT framework with a memory encoder and allows cross-attention from the decoder to the memory encoder. The cross-attention is used twice during decoding. First, to weight the sum of memory embeddings which contribute to the update of the decoder’s hidden states. Second, each attention score is taken as a probability of copying the corresponding token from the memory.
Experimental results
The experiments are performed on the JRC-Acquis corpus (European Union laws), for the Spanish-English and German-English language pairs in both directions. Unfortunately, the evaluation is performed only based on the BLEU score.
Several models are compared:
1) the baseline Transformer model,
2) the proposed approach, but using source-side similarity retrieval instead of cross-lingual retrieval
3) the proposed approach using a fixed cross-lingual retriever (not learned during training), and
4) the full model of the proposed approach.
The best results are achieved by the full model, for all language directions. The difference with respect to the baseline Transformer model is more than 3 BLEU points on average, giving more evidence that enhancing the Transformer model with a memory can improve the MT results. The results also show that the fixed cross-lingual retrieval does not yield significant improvement over the source-side similarity search. In contrast, the full model yields a substantial improvement. Thus learning the retrieval model parameters during training is effective. An experiment which is missing in the paper is with a learnable retrieval on a translation memory. This would allow us to see the impact of using a memory with monolingual data instead of parallel data.
Cai et al. also perform experiments in two scenarios: low-resource and model adaptation. In the low-resource scenario, the baseline model is trained on ¼ of the data, and the memory is used as a source of additional information. The results show that the larger the memory, the more the BLEU score is improved, suggesting that the approach is useful in this use case. Interestingly, the approach also works without retraining, i.e. with a memory which hasn’t been seen during training.
In the model adaptation scenario, corpora from five domains are used: medical, law, IT, Koran and subtitles. The baseline is trained with ¼ of the data formed by the concatenation of the five domains. Then for each domain, a memory consisting of the remaining data from this domain is used to enhance the model. The memory-enhanced models achieve BLEU scores about 2 points higher than the baseline on average, which is a good result given that in-domain data was already present in the baseline.
Finally, the presented memory-enhanced approach comes at a reasonable computational cost. Each training step is about 2.5 times slower than for the baseline Transformer, but less steps are required because it converges faster. The inference is about 1.3 times slower than the baseline.
In summary
Cai et al. propose an approach to memory-enhanced NMT which is different in two ways from the state of the art. Firstly, only monolingual data in the target language is required. Secondly, the retrieval model is learned during training, thus the retrieved sentences are the ones most relevant to the task. According to the BLEU score, the proposed approach outperforms the baseline transformer model and improves the state of the art in memory-enhanced NMT. It is also shown to be useful in the low-resource and data adaptation scenarios.

Author
Dr. Patrik Lambert
Senior Machine Translation Scientist