
Translation-Memory (TM) based neural machine translation (NMT) typically consists of searching a TM at inference time to retrieve the sentence pairs whose source side are most similar to the source sentence, and to use these retrieved sentences to adapt the model. This approach usually works very well when the retrieved sentences are very similar to the source, but could hurt translation quality when they are not so similar. Hence, the technique doesn’t work very well in the use case of a generic engine, where it is often the case that no sentence similar to the source is found in the TM. In issue #148, we commented on a paper which dealt with this issue by including the retrieval in the end-to-end training. Thus, the sentence pairs retrieved were not necessarily the most similar to the source sentence, but the most useful to reduce the translation loss. Today we take a look at a paper from He et al. (2021) that tackles the issue from another angle. It proposes joint training with and without the TM to ensure that the model works even when no useful information is provided by the TM.
Description of the Method
Sentence Retrieval
A first set of the top 100 similar bilingual sentences are retrieved from the training data with Apache Lucene. This set is then re-ranked with a more fine-grained criterion. To make inference as efficient as possible, only the most similar sentence pair is selected as TM.
Model architecture
The model architecture is a Transformer augmented with an example layer, as described in the left part of the following figure. 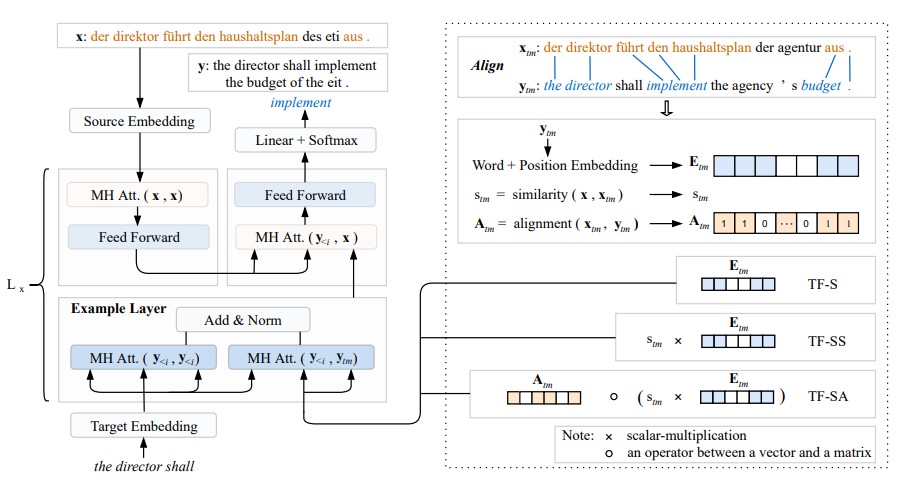
The example layer is composed of two multi-head attention operators, followed by an “Add & Norm” operator (a residual connection operator followed by layer normalization). The left multi-head attention is the same as in the Transformer, and it is defined on the current translation hypothesis. The right multi-head attention attempts to capture information from the TM, and it looks at both the current translation hypothesis and the encoded TM sentence.
The authors experiment with three different ways of encoding the TM sentence pair, illustrated on the right part of the figure above:
- Sentence (TF-S): the word embedding and position embedding of the TM target sentence are used (Etm in the figure).
- Sentence with score (TF-SS): the similarity score stm (0< stm<1) is added to the TF-S representation
- Sentence with alignment (TF-SA): as seen in the top right box in the figure, the TM source words matching the source sentence x (top left box) are in orange. The alignment between the source and target sides of the TM sentence pair is equal to 1 for the target words aligned to some matched (orange) source word, 0 otherwise. This gives more importance to the TM target words aligned to some TM source word matching the source sentence.
Training criterion
To avoid the situation where training with the example layer hurts translation quality when no good example is available in the TM, a joint training strategy is proposed. It consists of minimizing a joint loss function, which is the sum of the loss function with the TM sentence pair, and the loss function with null TM sentences. The first term guides the model to use the information from a TM for prediction, and will yield accurate translations for the input source sentences with high similarity to the TM. The second term teaches the model to output good translations without information from a TM.
Experimental results
The evaluation is performed with the case-insensitive BLEU score, on six translation tasks from the JRC Acquis corpus, and two generic translation tasks (WMT English-German and Chinese-English).
The TF-SA encoding method is found to perform better than the TF-S and TF-SS methods. This was expected due to the fine-grained alignment information encoded in the TM representation.
Without joint training, the TM-based model achieves large BLEU score gains over the baseline Transformer (TF) on the Acquis corpus (more than 10 points for the sentences most similar to the TM, about 5 points for the whole test set). However, these gains are observed to be mainly for those sentences with relatively high similarity with the TM (score superior to 0.3). In the range of similarity scores between 0 and 0.3, the TM-based approach performs worse than the TF. However, with joint training, the large gains are maintained in the range 0.3-1, and the TM-based model gets slightly better BLEU scores than the TF in the range 0-0.3.
The authors also test their model with no TM at all, and the results are not worse than for the baseline TF. This shows that the proposed approach makes it possible, with a single model, to handle the two use cases: with or without a TM.
The robustness with respect to sentences with a low similarity score is confirmed by the experiments on the generic tasks. In this case, the TM-based model achieves slightly better scores than the TF baseline (nearly 1 BLEU score more).
Finally, the inference speed of the model is 30% slower than the baseline TF, which is reasonable compared to other TM-based methods.
In summary
He et al. (2021) propose an effective way of introducing a retrieved TM sentence representation into the Transformer model. It encodes the alignment with words matching the source sentence in the representation. As in previous research, the authors observe that the gain depends on the similarity of the retrieved sentence with the source sentence. However, thanks to a joint training approach, with a loss function term with a TM and another one without a TM, the model learns to output good translations without useful information from a TM. This allows the proposed TM-based model to be as good as the baseline if no TM is provided, and to outperform the baseline even in a generic use case.

Author
Dr. Patrik Lambert
Senior Machine Translation Scientist