
Introduction
On our blog a couple of weeks ago (issue 116), Patrik explored fully non-autoregressive machine translation, highlighting the tricks such as dependency reduction that enabled quality to be maintained while retaining the speed-up gains over autoregressive MT. Today we revisit non-autoregressive translation (NAT), examining EDITOR by Xu and Carpuat (2020) which builds on the Levenshtein Transformer (see issues 82 and 86 for a recap), to bring both faster decoding and improvements in translation quality.In a nutshell
EDITOR introduces a new reposition operation which is more effective and efficient than the deletions and insertions of the Levenshtein Transformer. The result is to decouple lexical choice from word positioning, which makes intuitive sense, and improve quality on soft lexical constraints through the extra flexibility.Dual path imitation learning
They treat the problem as a sequence refinement one, modeled by a Markov Decision Process, iteratively refining the sequence by choosing one action. In particular, they integrate imitation learning, using decoder outputs to make policy predictions, to which they apply a given action (reposition or insertion) and receive a resulting reward. In the case of lexical constraints, these are included in the initial sequence, which otherwise is empty.
Decoder representations are used to make the policy predictions. Each refinement action is based on reposition and insertion operations:
- Reposition policy: unlike reordering, can delete tokens and can place tokens independently, enabling parallelisation at decoding time.
- Insertion policy: incorporates 1) a placeholder insertion classifier which predicts the number of placeholders to be inserted and 2) a token prediction classifier which replaces each placeholder with an actual token.
Actions are formally defined as a = (r, p, t), where a is a sequence of reposition (r), placeholder insertion (p) and token prediction (t), which can be applied in parallel. EDITOR is trained using imitation learning to efficiently explore all the valid action sequences which can lead to the reference translation. In particular, they incorporate:
- a roll-in policy which generates sequences to be refined,
- a roll-out policy which estimates the cost for all possible actions, given the input sequence.
Specifically, they deploy dual-path imitation learning, whereby they incorporate the reposition operation: for example, the initial sequence y0 is iteratively updated via roll-in policy updates. Roll-in policies reposition πrps and placeholder insertion πplh are depicted in the diagram below, where the learning process uses both during roll-in, so they can refine each other’s outputs. 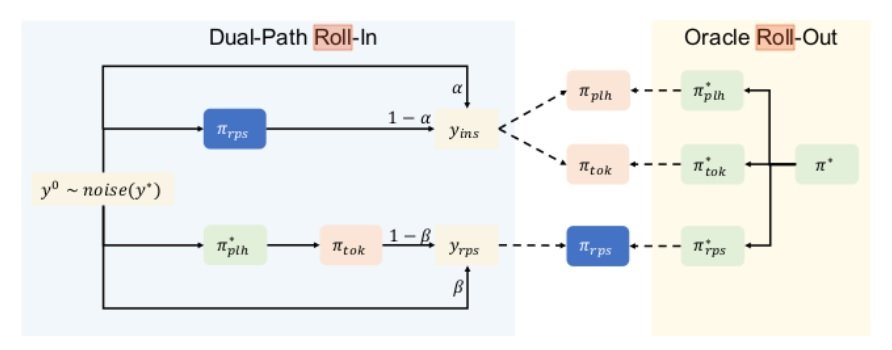 Dual path roll-in is called such since it creates 2 distinct intermediate sequences- reposition and insertion policy predictors can refine one another’s output during rollout (where Gu et al. (2019) used only insertion policy). The policy predictors are trained to minimize cost of reaching the reference. The reposition and insertion operations are designed such that Levenshtein edit distance can be used as the oracle, deploying dynamic programming to find the optimal action sequence.
Dual path roll-in is called such since it creates 2 distinct intermediate sequences- reposition and insertion policy predictors can refine one another’s output during rollout (where Gu et al. (2019) used only insertion policy). The policy predictors are trained to minimize cost of reaching the reference. The reposition and insertion operations are designed such that Levenshtein edit distance can be used as the oracle, deploying dynamic programming to find the optimal action sequence.
No change is needed to the decoding sequence in order to incorporate soft lexical constraints (as mentioned they are incorporated into the initial sequence). Hard constraints are enforced as per method examined in blog 82. For details on data and training, see paper.
Does it work?
They evaluate EDITOR with the same language pairs and datasets as Gu et al. (2019), and also on terminology constraints test sets of Dinu et al. (2019). EDITOR decodes 6-7% faster than the Levenshtein Transformer on Romanian-English (Ro-En) and English-German (En-De), and 33% faster on English-Japanese (En-Ja), with comparable or better quality as measured via automatic metrics. Under the soft constraints setting EDITOR preserves 7-17% more constraints than LevT, with higher quality and faster decoding. It outperforms the Autoregressive models with a beam of 4 on 2-10 constraints, and while the AR models can outperform the EDITOR, they require a larger beam to do so which then increases decoding time even further. Once constraints are increased to 10 then it still beats the AR models for En-Ja and Ro-En, even with a beam of 10. The table above gives an intuition of the effect that the reposition operation has when combined with the soft constraints, where we can see that it generates a more fluent and accurate translation.
The table above gives an intuition of the effect that the reposition operation has when combined with the soft constraints, where we can see that it generates a more fluent and accurate translation.
In summary
In summary, EDITOR’s novel repositioning operation reduces the amount of deletions and insertions, which makes decoding more efficient. Combined with a dual-path imitation learning strategy, it is able to generate output sequences more flexibly, improving quality, particularly when it comes to soft lexical constraints.
Author
Dr. Karin Sim
Machine Translation Scientist