
Introduction
In Issue#32, we covered the Transformer model for neural machine translation which is the state of the art in neural MT. In this post we explore a technique presented by Zhang et. al. 2018, which modifies the transformer model and speeds up the translation process by 4-7 times across a range of different engines.
Where is the bottleneck?
In the Transformer, we generate translation by looking at all the previous target words. The longer the sentences we're translating, the higher the complexity of the translation. This essentially means that translating long sentences can be quite slow.Average Attention Network (AAN)
AAN replaces the original dynamically computed attention weights by the self-attention network in the decoder of the neural Transformer with simple and fixed average weights. Given an input layer y={y1, y2,...,ym}, AAN employs a cumulative-average operation (equation 1, Average Layer), followed by a feed-forward network and layer normalisation (equation 2 &3, Gating Layer) as follows: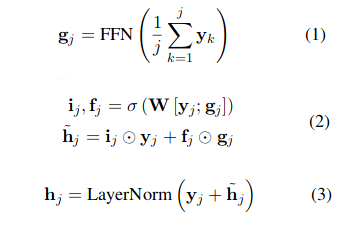 The following diagram from Zhang et. al. 2018 shows Average layer and Gating layer. The Average Layer summarises history information via a cumulative average operation over previous positions and it can be seen as a contextual representation for the j-th input. The gating layer improves the model’s expressiveness in describing its inputs.
The following diagram from Zhang et. al. 2018 shows Average layer and Gating layer. The Average Layer summarises history information via a cumulative average operation over previous positions and it can be seen as a contextual representation for the j-th input. The gating layer improves the model’s expressiveness in describing its inputs. 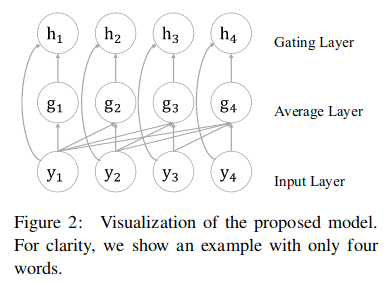
Transformer Decoder with AAN
The following figure shows the Transformer model with the AAN. Here we can see that the original masked self-attention is replaced with masked “Average Attention” in the decoding side (See Issue#32 for the baseline Transformer architecture).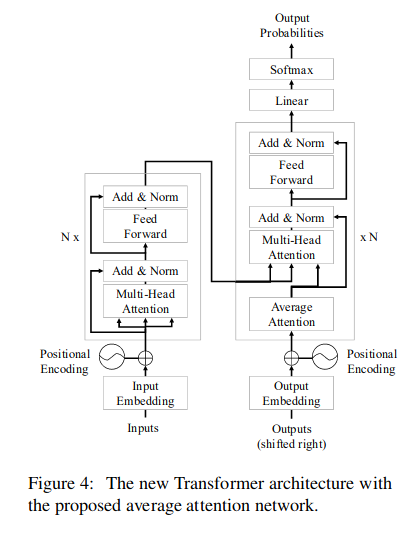
Results
AAN was evaluated against the baseline transformer on German, Finnish, Latvian, Russian, Turkish and Czech to/from English. All the models were trained and evaluated on one NVIDIA GeForce GTX 1080 GPU. The following table shows the decoding speed improvement for all the language pairs. We can see around 7 times improvement for English-Turkish.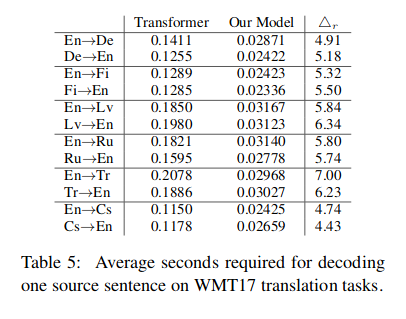 The BLEU scores with AAN were close to the baseline transformer model. With AAN, there was a slight decrease in BLEU score (up to 0.53) for all language pairs except German-English, where a marginal increase of 0.1 BLEU points was obtained. The maximum decrease of 0.53 BLEU points was observed for English-Turkish language pair.
The BLEU scores with AAN were close to the baseline transformer model. With AAN, there was a slight decrease in BLEU score (up to 0.53) for all language pairs except German-English, where a marginal increase of 0.1 BLEU points was obtained. The maximum decrease of 0.53 BLEU points was observed for English-Turkish language pair.