
Introduction
In Issue #32 we introduced the Transformer model as the new state-of-the-art in Neural Machine Translation. Subsequently, in Issue #41 we looked at some approaches that were aiming to improve upon it. In this post, we take a look at significant change in the Transformer model, proposed by Sukhbaatar et al. (2019), which further improves its performance.
Each Transformer layer consists of two types of layers: 1) attention layer(s) and 2) feedforward layer. Often, because of their novelty, attention layers are discussed more when we talk about Transformers. However, the feed forward layer is another major component in this approach and it should not be ignored. The Transformer model requires both types of layers to function properly.
Sukhbaatar et al. introduce a new layer that merges the attention and feedforward sub-layers into a single unified attention layer, as illustrated in the figure below. 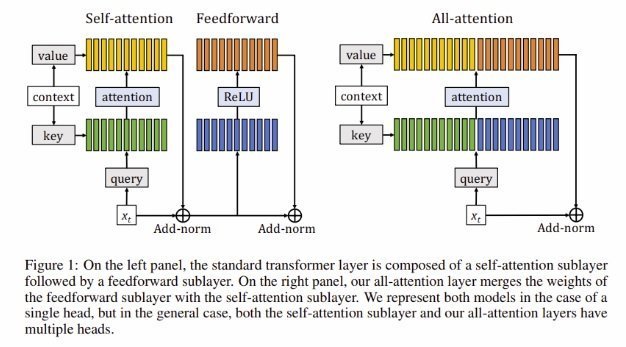 This unified layer, called all-attention layer, directly builds its representation from the context and a persistent memory block without going through a feedforward layer. This modification simplifies the structure without loss in the performance of the model.
This unified layer, called all-attention layer, directly builds its representation from the context and a persistent memory block without going through a feedforward layer. This modification simplifies the structure without loss in the performance of the model.
According to the researchers themselves, “Our layer applies the attention mechanism simultaneously on the sequence of input vectors, as in the standard self-attention layer, and on a set of vectors not conditioned on the input. These vectors are added to capture information that does not depend on the immediate context, like general knowledge about the task. They are shared across the data and, in some sense, forms a persistent memory similar to the feedforward layer.”
How does it perform?
On character level language modeling task, the all-attention model performs competitive to the current state of the art (Dai et al. (2019), a Transformer model with recurrence mechanism). It obtains 0.01 bit per character (bpc) better on enwik8 dataset and 0.01 bpc worse on text8 dataset while using 114M parameters compared to 277M parameters in Dai et al. (2019). When comparing with the baseline transformer (Al-Rfou (2018), having 64 layers and 235M parameters), the all-attention model obtain 0.08 bpc better on enwik8 and 0.05 better bpc on text8.
On word-level language modeling, the all-attention model which uses 133M parameters, performs 3.6 perplexity better compared to the model having 155M parameters. However, it performed 2.3 perplexity worse than the large model having 257M parameters.