
How to Measure the Word Translation Accuracy
Xu et al. (2020) propose strategies to evaluate the accuracy of word-to-word translation in Transformer layers. The standard Transformer (both the so-called “base” one and the larger so-called “big” one) stacks 6 encoder layers and 6 decoder layers.
The encoder layers do not directly output target words, thus the authors propose to predict the target words corresponding to encoder output representations via an alignment matrix obtained from cross-attention weights. The cross-attention weights help the decoder to focus on the right source words when it is generating the target words, and thus may act as word alignment. After application of the alignment matrix on the encoder layer output representations, a linear projection is performed before predicting the target words.
For the decoder layers, the target words are directly predicted after linear projection of the output representation of the analysed layer. However, the decoder involves two types of “translation”. The first one, performed by the self-attention sub-layer, predicts the next token given the previously seen token sequence. The second one, performed by the cross-attention sub-layer, predicts the next token by attending source tokens. The authors analyse the effect of these two kinds of translation on predicting accuracy by dropping the corresponding sub-layer of the analysed Transformer layer.
Analysis of Encoder and Decoder Layers
The analysis of encoding layers surprisingly shows that an already reasonable translation accuracy (40,7) is obtained at the source embedding layer (before the first encoder layer). This indicates that the translation begins even before the start of encoding, and not only in the decoding phase. The word translation accuracy steadily improves in each encoder layer, up to an accuracy of 49.2 in the last layer. The improvements brought by different layers are similar.
The analysis of decoder layers shows that the first layers (0 to 3, where 0 is the target embedding layer, just before the decoder) perform significantly worse than the first encoder layers. Most of the improvement is brought by layers 4 and 5, up to an accuracy of 70.1 at the last layer. Analysing the two types of translation, in the first layers (0-3), both types play a similar role. However, in the last layers, attending source tokens plays a more important role than considering the decoding history.
Trade Decoder Layers for Encoder Layers
From this analysis of the 6-layer Transformer (here is “base” model), we can remark that some decoder layers contribute significantly less to the word translation accuracy than the others. This leads the authors to suggest that there might be more “lazy” layers in the decoder than in the encoder, meaning that it may be easier to compress the decoder than the encoder. Compressing the decoder presents two advantages with respect to compressing the encoder: 1) it slightly reduces the number of model parameters, because the decoder layers include the cross-attention sub-layer, which is not present in the encoder layers; and 2) it greatly improves the decoding speed.
Thus the paper proposes to reduce decoder layers and replace them with encoder layers. In doing so, the results of the following table were obtained. 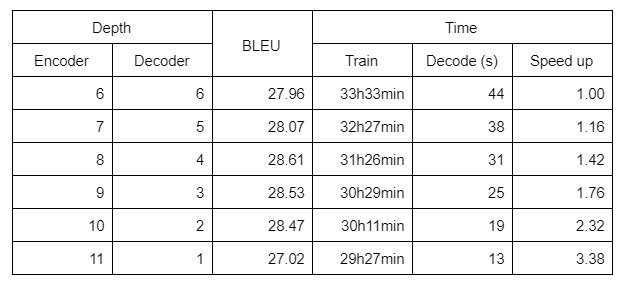 We can see that down to 2 decoder layers, trading decoder layers for encoder layers yields a small training time gain and large decoding speed-ups (up to 2.32 time faster with 10 encoder and 2 decoder layers), with no loss in BLEU score. BLEU score even improves a little.
We can see that down to 2 decoder layers, trading decoder layers for encoder layers yields a small training time gain and large decoding speed-ups (up to 2.32 time faster with 10 encoder and 2 decoder layers), with no loss in BLEU score. BLEU score even improves a little.
In summary
This analysis of word translation accuracy in a base Transformer shows that translation starts in the source embedding layer, and the accuracy progressively improves in the encoder. Translation accuracy is low in the first decoder layers, and greatly improves in the last ones, suggesting that some decoder layers are not vital. Trading decoder layers for encoder layers yield large decoding speed-ups with a slight improvement in BLEU score.
Author
Dr. Patrik Lambert
Senior Machine Translation Scientist