
Introduction
Pre-training has been used in many natural language processing (NLP) tasks with significant improvements in performance. In neural machine translation (NMT), pre-training is mostly applied to building blocks of the whole system, e.g. encoder or decoder. In a previous post (#70), we compared several approaches using pre-training with masked language models. In this post, we take a closer look at the method proposed by Liu et al. (2020), to pre-train a sequence-to-sequence denoising auto-encoder, referred to as mBART, from mono-lingual corpora across languages.
Multilingual Denoising Pre-training
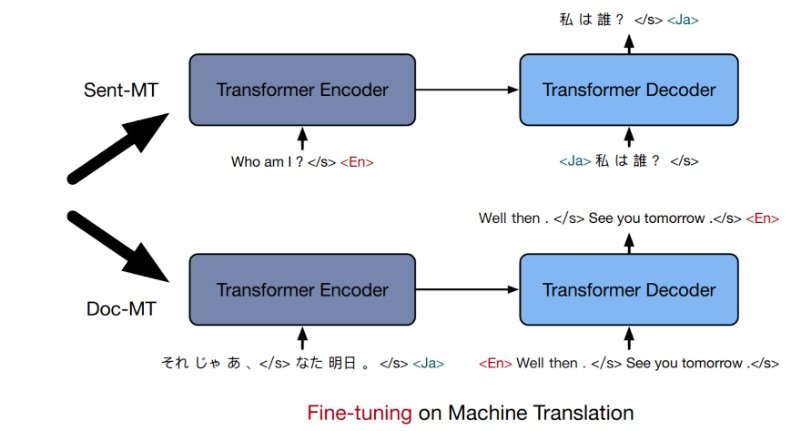
BART, proposed by Lewis et al. (2020), is a denoising sequence-to-sequence pre-training method for NLP tasks. The idea is simple: we corrupt the texts with a “noisying function” and then train a (denoising) auto-encoder that could reconstruct the original texts. mBART uses BART to train the auto-encoder on “large-scale mono-lingual corpora across many languages.” In the experiments, the noisying function corrupts the texts by masking phrases and permuting sentences, Liu et al. (2020). Compared to Masked Sequence to Sequence Pre-training for Language Generation (MASS), proposed by Song et al. (2019), mBART does not mask the input for the decoder and it introduces an additional noisying function to permute sentences when applied to document-level MT. The training is done once across all languages, and the trained auto-encoder can then be fine-tuned for a language pair. Fig. 1 shows the ideas of the pre-training of denoising auto-encoders (mBART) and its uses for MT. 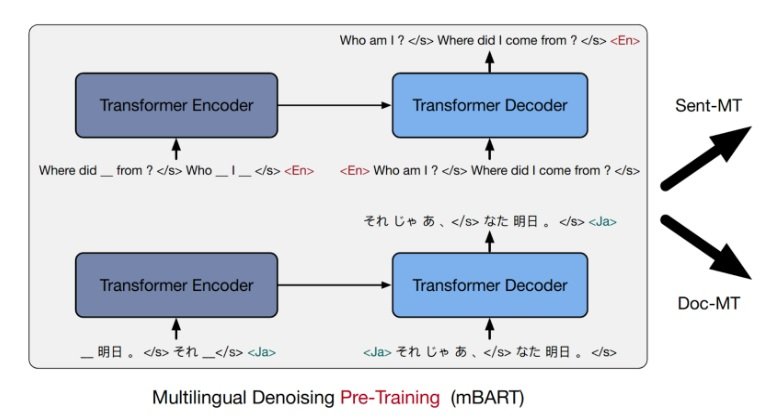
Figure 1. The denoising auto-encoders are trained by phrase masking (as shown in the diagram) and sentence permutation. In the two examples in English and Japanese, the sentences are re-constructed 100% correctly. The mBART model can then be fine-tuned for a specific language pair. Excerpted from Liu et al. (2020).
Experiments and Results
While the original BART only applied to English, the paper investigates applying to more languages using a subset of 25 languages extracted from Common Crawl (CC25). The pretrained mBART models are then used as initialization while training NMT models. Fig. 2 shows the performance improvement from using randomized parameter initialization to taking advantage of the pre-trained models.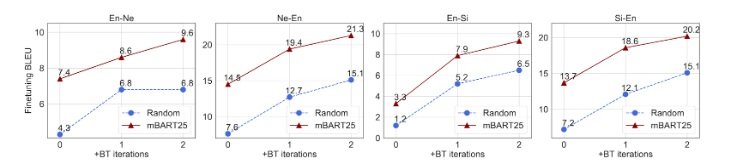
Figure 2. Comparison of performance of using randomization and mBART for NMT training initialization. FLORES dataset is used in this experiment, for Nepali–English and Sinhala– English, Guzmán et al. (2019). Excerpted from Liu et al. (2020).