
Introduction
Pre-training with masked language models (such as BERT) has shown impressive results in various Natural Language Processing (NLP) tasks. In post #24, we saw how a pre-trained BERT model is used to initialise the encoder in an encoder-decoder architecture for neural MT. In a recent post (#68), we saw an improved technique in which BERT representations are fused in the encoder and decoder of the Neural MT model using cross attention. In this post, we take a look at approaches that directly reconstruct masked text with an encoder-decoder architecture, producing a set of parameters which can be directly fine-tuned for neural MT.
Pre-training approaches
Song et al. (2019) propose an approach for Masked Sequence to Sequence Pre-training for Language Generation (MASS). In a source sentence x, they mask positions u to v. MASS pre-trains a sequence to sequence model by predicting the sentence fragment from u to v taking the masked sequence as input. An example is given in the figure below. The input sample has 8 tokens, the tokens x3x4x5x6 being masked. The model only predicts the masked fragment x3x4x5x6, given x3x4x5 as the decoder input for positions 4−6, the others being masked. Masking the other decoder input positions aims at extracting more useful information from the encoder side.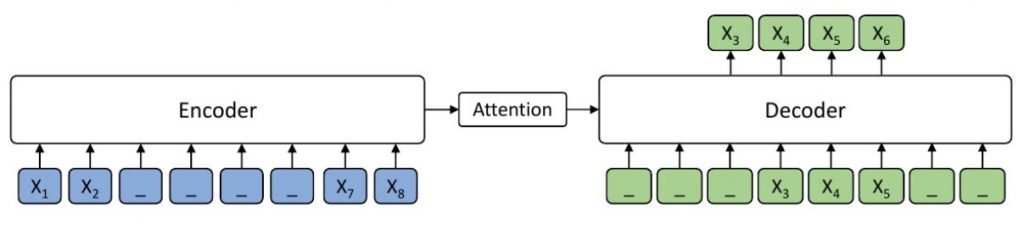 Liu et al. (2020) (mBART) extend this approach and reconstruct full texts instead of text fragments, and perform pre-training with a higher number of languages (up to 25). They use two types of noise. 35% of the words in each instance are replaced with a mask token. The order of sentences within each instance is also permuted. Both approaches use Transformers as a sequence-to-sequence model.
Liu et al. (2020) (mBART) extend this approach and reconstruct full texts instead of text fragments, and perform pre-training with a higher number of languages (up to 25). They use two types of noise. 35% of the words in each instance are replaced with a mask token. The order of sentences within each instance is also permuted. Both approaches use Transformers as a sequence-to-sequence model.
Results
Song et al. (2019) present results on unsupervised MT (with no parallel data). They use the MASS pre-training to initialise an unsupervised Neural MT engine. This approach achieves significant improvements with respect to the best approach so far, which was using BERT as the pre-training objective. For example, on English-French translation they obtained a BLEU score of 37.5 instead of 33.4.
Liu et al. (2020) perform an extensive number of experiments on supervised and unsupervised MT, as well as on document-level MT. On these tasks, the model obtained with mBART pre-training is respectively fine-tuned with parallel, monolingual and document-level parallel training data.
On supervised MT, they present results on 24 language pairs with varying training data size and show that mBART pre-training helps when the size of training data is less than about 10 million sentence pairs. With this size or larger training sets, they suggest that the effect of initialisation with pre-training is cancelled out by the number of training instances. To give an example, on English-Finnish, with 2,6 million sentence pairs, the improvement is nearly 7 BLEU points into English and 2 points into Finnish.
mBART models on 2, 6 or 25 languages were compared. The conclusion is that pre- training on more languages helps most when the monolingual target language data is limited.
The authors also report experiments with back-translation in addition to pre-training on several language pairs, such as English-Burmese. In these experiments, back-translation of the same monolingual data as used for pre-training yields a further improvement in BLEU score.
They also show that pre-training helps for languages not present in pre-training. For example, translation from Dutch to German gets a 5 point BLEU score improvement with two pre-training models trained respectively on 2 and 6 languages, both excluding Dutch and German. This suggests that the pretrained Transformer layers learn universal properties of language that generalize well.
In this spirit, an unsupervised translation engine fine-tuned on each of 12 considered languages is directly tested on the others. For example, the engine fine-tuned on English and Arabic monolingual data is used to translate from English into Italian. Surprisingly, the translation quality is reasonable (BLEU score of 30.6). This again suggests that pre-training is able to capture some universal properties of language.
In summary
Sequence-to-sequence pre-training improves translation quality for low- and medium resourced languages. In supervised MT, this means language pairs for which less than about 10 million training sentence pairs are available. It also helps on document-level MT and unsupervised MT. The good news is that the pre-trained models only need to be fine-tuned with specific data, which makes their use easier. The even better news is that pre-training is also helpful for languages not included in pre-training, suggesting that it partially captures universal properties of language.
Author
Dr. Patrik Lambert
Senior Machine Translation Scientist