
Introduction
Measuring MT Quality Without a Reference
This week we will discuss Practical Perspectives on Quality Estimation for Machine Translation by Zhou et al. (2020). MT Quality Estimation is the task of assessing the quality of machine translation without already having a reference translation to compare to. This estimation can take multiple forms. One is a score-based MT metric of the same type as those that use references. Previously, we’ve discussed both COMET (#109) and PRISM (#156), two MT metrics which have reference-free versions. Another form of quality estimation is predicting the number of edits necessary to correct an MT output. A third type is one that classifies as GOOD or BAD each word of the output and often the empty spaces between words – a bad space is one that should contain something but doesn’t. This last type is more specific than the other two and thus presents a bigger challenge.
Predicting the number of edits is useful if you are planning to post-edit a document. It can tell you which sentences need a lot of work, and which need little (or none). To formalize this, we define HTER (Human Translation Error Rate) as the number of words/tokens needing to be changed, added, or removed from a translation to correct it, divided by the sentence length. For example, here are some machine translations into French and their HTER scores:
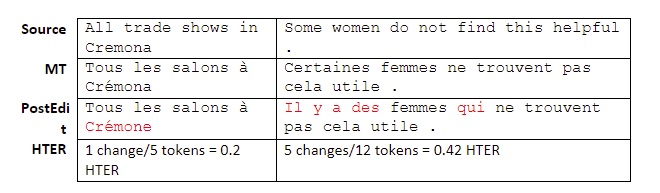
Note that to measure HTER you don’t use a reference directly. Instead, the MT output needs to be edited with the minimum number of changes to correct it.
Quality Estimation as Regression
Given a sufficient number of training examples, one can train a model to predict the HTER score given the source and machine translated sentences. Some of our first explorations into MT quality estimation attempted to do exactly this. See the graph below for an example. This graph depicts all the points in our test set, plotted with predicted vs. actual HTER. The result has a correlation of 0.5 and a Mean Absolute Error (MAE) of 0.18. It was difficult to determine if the numbers were good or not, but the picture clearly shows that these predictions were not very practical. If our model predicted an HTER of 0.25, this could correspond to an actual HTER anywhere between 0 and 1. Even worse, the points along the right side of the graph, those with an actual HTER = 0 (i.e., the perfect sentences), were always predicted with some positive HTER value, mostly between 0.1 - 0.3. We struggled to answer how this could be useful for anyone.
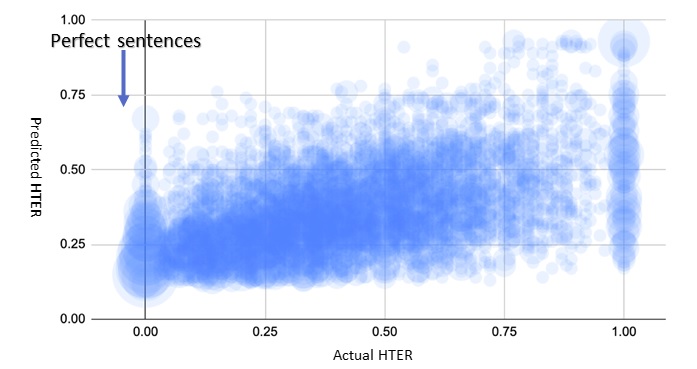
This is where the paper by Zhou et al. (2020) fits in: they argue that the common paradigm of regression (predicting a numeric score) is not very practical. The complexity of predicting an HTER score per sentence isn’t useful when the user really wants to know if the sentence needs editing or not (i.e., HTER = 0). Regression models are evaluated with metrics such as MAE or correlation, which reward how well the model predicts the score evenly across the range of values. But we aren’t really concerned if the model correctly predicts a score on low quality output (0.6 vs. 0.8), we really only need it to be accurate for the high quality sentences. But can we meaningfully distinguish those based on the predicted HTER? Looking at the figure above: where would you draw a horizontal line to separate the good sentences (actual HTER=0) from those that need editing?
Quality Estimation as Classification
Instead, Zhou et al. (2020) argue, turning quality estimation into a binary classification problem is simpler, more understandable, and more feasible to train. Marking each sentence as either good (+) or bad (-) provides a truly useful distinction for the downstream MT user, either a post-editor or interested reader. We can meaningfully discuss the results on a corpus in terms of accuracy, F1, or precision and recall. And we’ll see that training a model directly on classes leads to better results.
A binary classifier can also be tuned to predict with increased precision or increased recall. High precision is the most valuable for quality estimation: sentences predicted good are truly good, a practical requirement if we are using the classifier to bypass human editing or review. Recall is secondary for this use case, but still important: a higher recall means we have correctly identified more of the sentences that are truly translated well and this can save us from doing unnecessary work. To this end, the authors suggest a new metric: R@Pt = Recall at a precision threshold, and suggest a precision threshold of 0.8 or 0.9 as practical, so they suggest evaluating systems with the highest recall and at least 0.8 precision (R@P0.8) or 0.9 precision (R@P0.9).
In our judgment, this recasting of MT quality estimation as a classification problem and the suggestion of evaluating recall at a precision threshold are the most useful contribution of the paper.
Results
The authors then use two MT models to generate features as input to binary classification models:
- Quasi – based on the earlier QE model of Zhou et al. (2019), and
- NMTEx – based on the Transformer model described by Caswell et al. (2019)
To both they add a useful mismatching feature described by Wang et al. (2018). They then optimize each model’s hyperparameters to find the best model at precision thresholds of 0.8 and 0.9.
The results on the WMT17 Quality Estimation datasets are shown in the table below. Note that the WMT17 QE dataset was originally labeled with HTER scores for each sentence. The authors converted HTER=0.0 to good, while all scores > 0 were converted to bad. The good label was on 9-15% of the data for English-German (En-De), and 15-44% of the data for German-English (De-En).
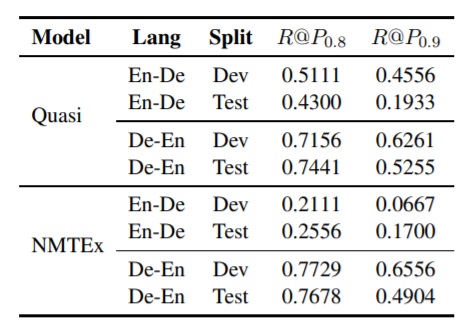
Note first that the En-De direction seems more challenging to predict than the De-En direction. Also, the Quasi model performs better overall, but both models fail to produce high recall scores at a precision threshold of 0.9. The authors also trained regression models (for En-De only) to predict the full range of HTER scores using the same sets of features as the classification models. They did this to see if model predictions below a threshold (e.g., HTER < 0.1) could predict the good class. However, similar to our early experiments, when the authors tried to determine a threshold value to discriminate good from bad, they were unable to reach a precision higher than 0.64 with any threshold value.
It is also noteworthy that these models were state-of-the-art in 2019, but the field has progressed since then. We can expect that this classification recasting idea, when applied to a more recent model, might give better results. Sun et al. (2021) recently used classification rather than regression for state-of-the-art QE models, but their focus was on compression to optimize models for efficiency rather than high precision.
In summary
MT Quality classification using labels such as good or bad, as proposed by Zhou et al. (2020), is both simpler and more effective than scores for downstream applications. Scores from regression models may be possible to convert into classes but reformulating the models to directly predict classes leads to better results. By evaluating classification models on R@Pt one can expect both minimal false positives (mistaking a bad translation as good) and plenty of true positives (correctly labeling as many good translations as possible).

Author
Dr. Steve DeNeefe
Research Manager