
MT Evaluation via Zero-Shot Paraphrasing
Automatic evaluation metrics play a significant role in determining which neural machine translation (NMT) engine to deploy, or even in some cases which MT supplier to go with. Yet there is still no single reliable automatic metric. In previous blog posts we have considered various metrics (#109, #86), in addition to detailing the problems in current evaluation methods (#143, #141, #90). In today’s blog post we focus on work by Thompson and Post (2020) on another metric, Prism, which is simple, runs on 39 languages, and can also be run without a reference as a quality estimation metric.
Prism in a nutshell
Prism scores the MT output with a sequence-to-sequence paraphraser, conditioning on either the human reference or the source text. It is trained on multilingual parallel data, and in essence is a multilingual NMT system, with an encoder which maps the sentence to a (loosely) semantic representation, and a decoder which maps it back to a sentence. At evaluation time it is used to force decode, in effect “translating” e.g. Czech to Czech. The score is based on how well it paraphrases the reference.
Details
In essence, the paraphraser force-decodes and estimates the probabilities of the MT outputs, conditioned on the human reference, or alternatively the corresponding source segment. The probability that the paraphraser assigns to the t th token in output sequence y given previous output tokens and the input sequence x is p(yt |yi<t , x). The table below illustrates how token level log probabilities are conditioned on the input sequence (the reference in this example), and penalized when they differ.
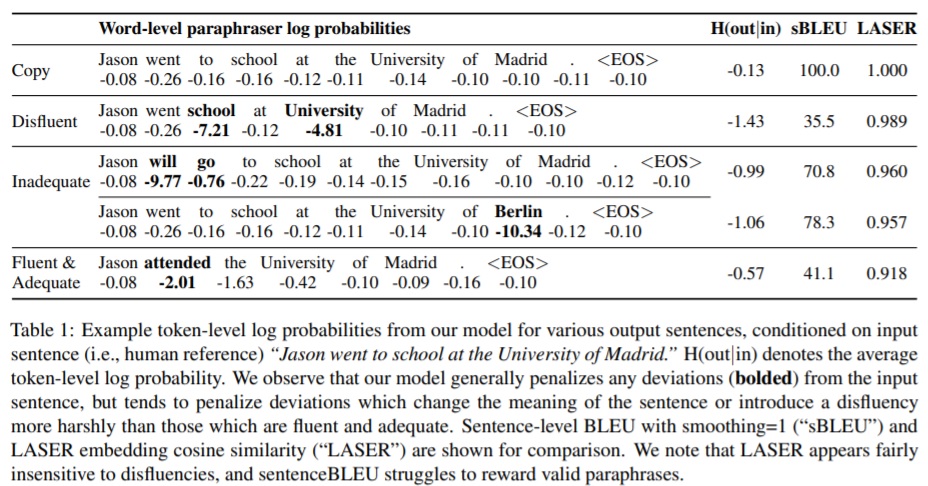

They experiment with scoring both on the MT system output (sys) conditioned on the reference (ref), and on the reference (ref) conditioned on the MT system output (sys). The expectation is that the former is the best measure of quality, however scoring in both directions mitigates the risk of penalizing information in one sentence which is missing in the other. In experiments, they found that the length-normalized log probability (H, above) slightly outperforms un-normalized log probability (G).
Their presumption is that “the output sentence that best represents the meaning of an input sentence is, in fact, simply a copy of the input sentence, as precise word order and choice often convey subtle connotations”. Whereas a regular paraphraser is trained to convey “the meaning of the input while also being lexically and/or syntactically different from it”. Therefore they compare results with a paraphraser baseline. Although, of course, the main task of a translation is to convey the meaning of the input, and there may be various ways of doing so.
The fact that the model is multilingual means that it can also score conditioned on the source sentence instead of the human reference, which makes it a very interesting proposition for evaluation of MT output where there is no reference (most situations).
The final metrics (after refinement on devset) are defined as below:
They use the WMT18 MT metrics data to experiment with and determine how best to integrate the token-level probabilities. Results are reported on the WMT19 system and segment level tasks. The training data comprises 99.8M sentence pairs, drawn from WikiMatrix, Global Voices, EuroParl, SETimes and UN (details in Thompson and Post, 2020).
Results
As can be seen in the table of segment-level human correlation (τ) scores for pairs into English displayed below, Prism performs competitively with other metrics (for more extensive results, refer to the paper). Bold indicates the top scoring methods.
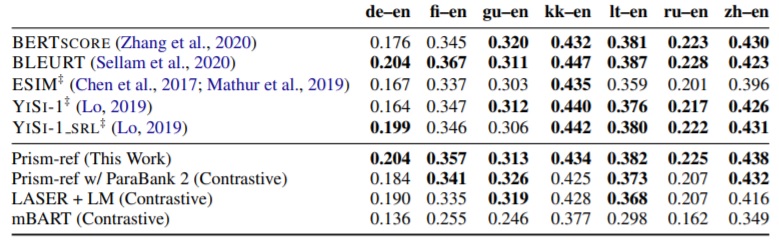
For QE as a Metric, so referenceless evaluation, it also performs well. The authors include other comparisons such as LASER, BERTscore and BLEURT. For LASER they find that it is insensitive to disfluencies, and so augment it with scores from a language model. Whether it is stronger on accuracy is not investigated.
Prism-ref outperforms Prism-src, which is unsurprising given that the authors acknowledge that as an NMT system it is not strong. Moreover, evaluating against the source is a harder task. Worth noting is that according to WMT19 the reference-based language pairs were annotated via anonymous crowdsourcing, and the reference-less evaluations were largely by MT researchers, ie. not professional translators. As clearly set out in blog post #80 and #81, the WMT task is flawed in terms of the translation quality of the datasets and the proficiency of the evaluators, who are generally not professional translators. Sadly, correlation to the annotations of these evaluators is still the main way that new MT research is benchmarked. And while this may be a practice used in the MT research community, it doesn’t provide proper evaluation of any metric.
In summary
Thompson and Post (2020) present Prism, a multilingual NMT system deployed as a paraphraser, which can be used as a metric based on either a reference or a source segment. On WMT19 data it performs strongly, and could potentially be a useful metric. To fully evaluate how robust and performant it is, it should be properly evaluated with human translators, and ultimately in real translation workflows.

Author
Dr. Karin Sim
Machine Translation Scientist