
Can target lemma annotations help to get terminology right in MT?
Introduction
Getting terminology translated properly is a well known challenge for Machine Translation (MT) and an important element when measuring translation quality (both human and machine). In fact, forcing terminology, or getting terminology right is a frequent request from our customers. But getting it right is not a trivial task, and as researchers quest the best approach to do so, we follow their advances in this blog series. As we saw in issue #100, around 13% of our blog posts have been devoted to it.
Today we look at a recent paper by Bergmanis and Pinnis (2021), in which they explore yet another way of getting terminology right: using target lemma annotations. Their work follows on the research by Dinu et al. (2019) and proposes a modification to it. The authors also compare the results they obtained to those obtained following another recent method proposed by Exel et al. (2020), which we covered in issue #108. The novelty of their approach lies in the fact that Bergmanis and Pinnis attempt to not only translate the terms correctly, but to do so with the correct morphological form, a challenge, particularly for highly rich morphological languages.
Previous approaches have focused on what is known as “constraint decoding”: assuming that we know the correct translation and form for a term, we can “force” its translation in the target language. Just to illustrate this, imagine that we wanted to force the translation of “teacher” in English as “profesor” in Spanish. That can be done, but, translations will not be accurate when the teacher is female (“profesora”) or we want to refer to various teachers (“profesores”, or “profesoras” if they are female). The current approaches have as a limitation that we would then need to have all possible forms of the word and their translations, so that we can force them. However, in some cases, like in the example above, this would not guarantee an accurate translation, as the gender in English may only be inferred from the context in the sentence.
Dinu et al. (2019) proposed to amend source language terms with their exact target annotations (ETA). That way, the neural MT (NMT) model was able to learn whether a token was a source language term, its translation, or a regular word. Their limitation, as we stated above, is that the translations would be copied verbatim.
The proposed method: target lemma annotations
What the authors propose is to first annotate random source words in the training data. This minimises the need for curated bilingual dictionaries that will be subsequently used to prepare the training data. Then, instead of providing the translations that are expected for each word, they use target lemma annotations. Their hypothesis is that in so-doing, the model will learn the correct translation, but also the correct word form of such translation. Their approach is thus similar to the one proposed by Exel et al. (2020), with one slight but important modification: While Exel et al. did not annotate terms for which their base form differed by two characters at most from their expected translated form, Bergmanis and Pinnis do.The experiments
To test their approach, Bergmanis and Pinnis take various morphologically rich languages: Lithuanian (lt), Latvian (lv), Estonian (et), and German (de). All their experiments are from English into those languages, and they use the English>German language pair as a way to compare the results obtained by their approach against previous approaches.
In order to carry out the target lemma annotations they lemmatise and part-of-speech (POS) tag the target side of their training corpora and then using a word aligner (fast_align), they learn the correspondences between the lemmas in the target side of the corpus, and the fully inflected word forms in the source. They only annotated verbs or nouns, and the words to be annotated were selected combining two random thresholds, one at sentence level, and one at source word level.
Following the annotation process, they then trained an NMT model whose performance was compared against a baseline engine trained without any terminology constraints, an NMT engine including constraint decoding for forcing term translations (Post and Vilar, 2018), and an NMT engine using the ETA approach proposed by Dinu et al. (2019).
As test sets, they took a general domain data set annotated with exact surface forms of general domain words from IATE and Wiktionary and a test set from the automotive domain. The general domain data set was used as a way to validate that they had successfully reimplemented the work by Dinu et al. (2019) and was only used for the English>German language pair.
The results
They evaluated their results both by means of automatic metrics (BLEU and lemmatised term exact match translation accuracy) as well as by performing a human evaluation of the English>Latvian translations retrieved, whereby four professional translators were asked to assess the correctness of the translated terms, both in terms of lemma and form accuracy.
The automatic evaluation results are interesting. When the authors compare their approach with the already existing data set, the Target Lemma Annotations (TLA) do not yield better results. The BLEU score is very similar to the Exact Target annotations (ETA) approach, and the accuracy in terms of term translation is better. However, none of these two approaches surpass the accuracy obtained when using constraint decoding (CD).
When they use their automotive test set and focus on further languages, a similar observation can be made: their results, as well as the ones from the ETA approach are consistently better than the baseline and the constraint decoding approach, but the accuracy in terms of term translation, drops. In fact, for English>Estonian and English>Latvian, their term translation accuracy is lower than the one obtained using the ETA approach. 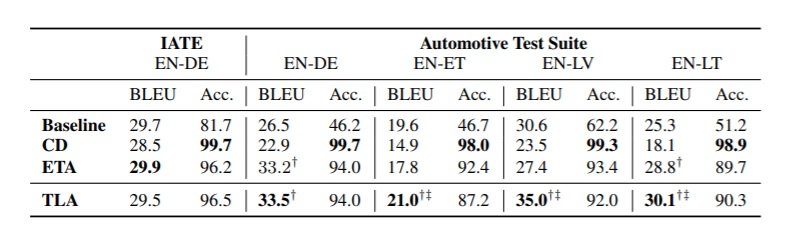 The authors, along with four professional translators, analysed the results obtained for the English>Latvian language pair. They analysed 100 random sentences from their test set, which contained 147 terms in total. As can be seen in the left-hand side of the figure below, in this case their approach seems to be the most accurate one, as 92.9% of the terms are translated correctly, while the ETA approach only gets 45.2% of the terms right. In terms of which system yields better quality translations (right-hand side in the Figure below), it seems that the TLA approach yields equal or better results than the baseline and the ETA approach.
The authors, along with four professional translators, analysed the results obtained for the English>Latvian language pair. They analysed 100 random sentences from their test set, which contained 147 terms in total. As can be seen in the left-hand side of the figure below, in this case their approach seems to be the most accurate one, as 92.9% of the terms are translated correctly, while the ETA approach only gets 45.2% of the terms right. In terms of which system yields better quality translations (right-hand side in the Figure below), it seems that the TLA approach yields equal or better results than the baseline and the ETA approach. 
In summary
The approach proposed by Bergmanis and Pinnis seems to yield positive results for a variety of morphologically complex languages: Latvian, Estonian, Lithuanian and German. Their approach consists of lemmatising and part-of-speech tagging the target side of the training corpus and applying word alignment to help the model learn which should be the correct translation form of a term.
Their results show that in terms of overall translation quality, their approach, similarly to the one proposed by Dinu et al. (2019) and Exel et al. (2020), yields better translations than a constraint decoding approach, where term translations will be forced and hence always right, but at the cost of sacrificing the quality of the system (sometimes even causing it to have a worse quality than a baseline engine with no terminology constraints). However, also similarly to previous approaches, the term translation accuracy is lower, as sometimes translations will be wrong.
A caveat from this approach is that it relies on the existence of accurate POS taggers for all languages, and this is not a given. Some languages lack good POS taggers, or may have a good POS tagger for a general domain, but not for a specific one. The results obtained are particularly interesting for real-world MT applications, as getting terminology right in MT right now is still a matter of choosing whether we want to get all terms translated right at all times but risking translation quality, or rather know that not all terms will be translated accurately, but the overall translation quality will be better, a discussion that we often have with our clients.

Author
Dr. Carla Parra Escartín
Global Program Manager