
Hello, again! When we started The Neural MT Weekly back in July 2018 it was originally intended to be an 8-part series...and here we are, 100 issues later! It's a great milestone to achieve and it's a testament to the authors, the topics they choose, the quality and accessibility of their writing.
Across the 100 issues, we've had 13 different authors from the Iconic team as well as guests. We've had hundreds of thousands of page views, lots of engagement across our social media channels, and it has even spawned its own webinar series!
We've been delighted to hear that many researchers in the field have the series bookmarked for reference, that the blogs are used as teaching aides in university courses on Natural Language Processing, and, awesomely, some of our blogs will soon be translated into Chinese for our growing audience.
In the previous 99 issues, we covered a lot of different topics charting the evolution of Neural Machine Translation. In this centenary issue, Iconic's Global Program Manager, Dr Carla Parra Escartín, is going to take a retrospective look at the key developments that we've seen and summarised. Enjoy! - Dr. John Tinsley, MD & Co-Founder
Introduction
The Neural MT Weekly blog series was kicked off just over two years ago. The series is a weekly blog where members of our scientific team at Iconic, as well as esteemed guests, pick a recently published paper on a topic in Neural Machine Translation (NMT) and write a summary of its findings and practical relevance. As a company working with an emerging technology like Neural MT, it is really important that we at Iconic keep our eye on the ball as things evolve. If we pick a particular implementation, and rest on our laurels, we can quickly fall behind. So, internally, when Neural MT came on the scene, we needed to find a way through which we could continue to work on production deployments and client needs, while also staying up to speed with the latest developments in the field. That started as a reading group between our scientific teams and ultimately manifested itself in our Neural MT Weekly blog.
Time sure flies when you’re having fun, as it seems like just yesterday when we first kicked the series off in July 2018 with a post called “Scaling Neural MT”. As the name suggests, the blog focused on decreasing the amount of time it takes to train Neural MT engines (which at the outset, was quite some time, despite the massive computing power behind it). Fast forward to today, and we have 100 blog posts published in The Neural MT Weekly.
100 issues of The Neural MT Weekly in a nutshell
Taken as a whole, our blog provides quite an accurate snapshot as to which topics researchers and developers have been focusing their efforts on. For this 100th issue we collected all of the blog posts (excluding a few special edition “use case” issues), categorised them by topic, and looked at the distribution of topics across the whole blog series. The findings, which you see on the figure below, give a picture of the R&D landscape within the Neural MT field. 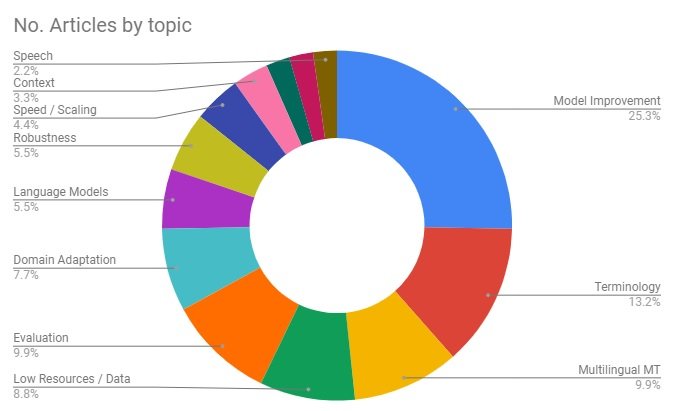 Looking at the most prevalent topic, Model Improvement, which is a bit of a catch all category for posts and papers which looked at more fundamental, general improvements to the underlying algorithms, accounts for almost 27% of all posts. This is actually a more recent development as well, with around half of these coming in the last 6 months or so.
Looking at the most prevalent topic, Model Improvement, which is a bit of a catch all category for posts and papers which looked at more fundamental, general improvements to the underlying algorithms, accounts for almost 27% of all posts. This is actually a more recent development as well, with around half of these coming in the last 6 months or so.
Probably the most pre-eminent of these was issue #32 entitled “The Transformer Model: State of the art Neural MT” which took a look at Google’s paper that did not use one of the traditional approaches using Recurrent Neural Networks or Convolutional Neural Networks. Rather, it introduced the concept of the “attention mechanism” and feedforward layers at various levels of the network to train the whole end-to-end pipeline. Other “Model Improvement” posts looked at other types of self-attention models (e.g. #46 - Augmenting self-attention with persistent memory; #73 - Mixed Multi-Head Self-Attention for Neural MT), transfer learning (e.g. #54 - Pivot based transfer learning for Neural MT; #74 - Transfer learning for Machine Translation), and noisy channel modelling (e.g. #57 - Simple and Effective Noisy Channel Modeling for Neural MT), among other topics.
Aside from these, the remainder of the posts looked at more specific topics, with almost 13% dealing with terminology and vocabulary coverage, almost 10% on multilingual Neural MT models, about 9% on data creation and low resourced languages, as well as almost 10% on machine translation evaluation and 7.5% on domain adaptation.
If we look at this data from another angle, we can see how many articles this corresponds to. 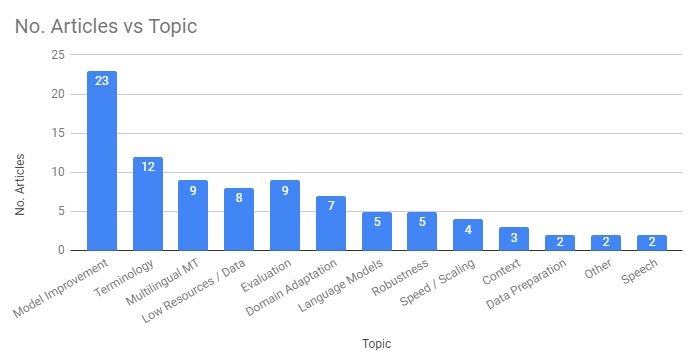 Aside from the topics we just mentioned, other recurring topics in the series have included 5 posts on Language Models and another 5 on Robustness, 4 posts on Speed and Scaling of Neural MT and others on incorporating contextual information, data cleaning and preparation, and speech translation.
Aside from the topics we just mentioned, other recurring topics in the series have included 5 posts on Language Models and another 5 on Robustness, 4 posts on Speed and Scaling of Neural MT and others on incorporating contextual information, data cleaning and preparation, and speech translation.
Most common topics portrayed in our blog series
1) Terminology and Vocabulary coverage
Here we are actually conflating two topics. One deals with the translation of unknown or out of vocabulary terms, while the other deals with the translation of words in a specific way.
Regarding unknown words, the first issue that arose with NMT was how these were treated. With Statistical MT (SMT), the source word was simply copied in the target if unknown. We could also identify these and perhaps treat them in a post-process. With NMT, there is no explicit link - or alignment - between the source and its translation (this is lost somewhere between the encoder and decoder) thus unknown source words are simply omitted from the target, or replaced with an UNKNOWN token. This is obviously not desirable, particularly as it could be common.
The proposed solution was to split unknown words into subwords, down to even the character level, using an approach called byte-pair encoding. This is based on the intuition that various classes of words - such as in heavily inflected languages (Russian), compounding languages (German), and character-based languages (Chinese) - are translatable using smaller units than just words. This worked really well and is now pretty much a staple in today’s NMT engines. Clearly it’s more effective for some languages than others, but it ultimately removes the issue of untranslated words in NMT output.
As for terminology, this is a much bigger challenge. It was one of the key issues that held up Neural MT from being production ready out of the blocks - mainly because this was an issue that was “solved’ with SMT. With SMT, we could put tags around certain words and tell the decoder to translate them in a particular way. This was in essence a guarantee that is no longer there with NMT, due to the fact that it’s an end to end process rather than a sequence of steps whereby we can “inject” such terms.
The fact that this is an ongoing issue in Neural MT is evidenced by the fact that our first post on the topic was issue #7 (Terminology in Neural MT) in August 2018 and more recent posts are issues #76 (Analyzing Word Translation in Neural MT Transformer Layers), #77 (Neural MT with Subword Units using BPE Dropout) #79 (Merging Terminology into Neural MT) in April of this year, and just a few issues back, it reappeared when talking about the translation of named entities in issue #96 (Using annotations for machine translating named entities).
Early approaches were quite simple - they involved replacing a term with a variable in source that would remain untranslated, and then putting the correct term back as a post-process. This was effective to a point, but could cause issues due to unexpected input, and also required external alignment information for correct placement of the terms in the target.
A more elegant approach is known as “Constrained Decoding” which essentially restricts the model from choosing translation candidates that don’t contain specific terms. While this works well on a high level, it’s computationally quite expensive with the complexity linear in the numbers of terms you want to use, i.e. the bigger the terminology list, the slower the translation.
Other approaches include a variety of methods by which models are trained to use certain terms, and to allow for terms to be injected at runtime with certain markup, similar to Moses. All of these approaches have their respective pros and cons, but none of them are as simple and as lightweight as we had in SMT.
What we’ve found at Iconic is that there isn’t really a silver bullet yet. There’s no single ideal way in which to apply terminology. Some approaches are more effective than others, but are more cumbersome (i.e. they require the updating of models, which takes time). Ultimately, we look at it on a case by case basis today, and the approach we go with depends on the engine we’re building and the needs of that specific client in terms of accuracy, speed, etc.
2) Multilingual Machine Translation
This is the idea that we can have a single neural MT model that has the capability to translate between multiple languages. The concept is similar to that of a pivot language, except it’s actually inherent to the model rather than being distinct steps.
It is kind of related to the topic of low-resourced languages insofar as the broad approach can allow us to translate between language pairs where we don’t have a lot of direct training data.
So consider the example of the three languages English, Russian, and Korean. In practice, we probably can get our hands on a lot of English-Russian and English-Korean parallel data, but it is unlikely there’s a lot of Russian to Korean parallel data. The idea here is that by training a model jointly on English Russian and English Korean, we can indirectly learn how to translate between Korean and Russian. This is known as zero shot dual learning, and the implementation has been referred to as Zero Shot Machine Translation.
In very simplistic terms, the way it works is as follows. As per the example on the figure below, we have a Russian - English corpus, and we have an English - Korean corpus. 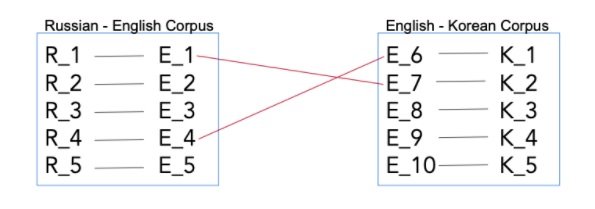
Let’s say that the English sentence “R_1 - E_1” in the Russian English corpus is actually the same as sentence “E_7 - K_2” in the English korean corpus, we can therefore infer that Russian sentence “R_1” and Korean sentence “K_2” are translations of one another. That’s more or less it. And it works. It sounds simple, but of course it is quite complex 'under the hood' and is very computationally expensive.
Again, this is not a silver bullet. Research to date shows that in the above scenario we still get better English to Russian results if we just train a regular engine rather than a multilingual one. Similarly, in some cases, classical pivoting still comes out on top too, but this is a massively interesting space and has particularly important implications for low resourced languages, too.
If you are interested in reading more about this approach, issue #6 (Zero-Shot Neural MT) would be a good starting point and you may also want to check other issues such as #37 (Zero-Shot Neural MT as Domain Adaptation), our guest post in issue #38 (Incremental Interlingua-based Neural Machine Translation), or issue #42 (Revisiting Interlingua Neural Machine Translation).
3) Data creation and Low Resourced Languages
Low resourced languages can be broadly defined as those languages where we don’t have a lot, if any, parallel training data with which to build MT engines. So what can we do in this scenario? Obviously one approach is multilingual MT or pivoting, which we just revisited. But aside from that, there are two other approaches, loosely related, that have had the attention of researchers, namely “unsupervised training” and “synthetic data”.
Synthetic data is basically the idea of using an MT engine to create parallel data. For example, we have a small English to Russian MT engine, but we have a lot of monolingual English data. Therefore, we use that MT engine to translate the monolingual data and that leaves us with a large amount of parallel data with which to train a larger, and in theory better, MT engine. This is also known as back translation (you can find out more about it in issue #5 - Creating Training Data for Neural MT), and while it looks like we may be introducing noise and low quality to the training data, in practice it has actually worked quite well! So much so that it triggered researchers to begin digging deeper and understanding better, things such as: "What is the optimal proportion of real vs synthetic data?", "What type of monolingual data is best?" and "How good does the base MT engine need to be, at a minimum?".
We, too, were skeptical about this approach at the outset but we tried it out for a Turkish to English legal MT engine a few years ago and it worked really well, so it is now very much a weapon in our arsenal.
As for unsupervised training, this is essentially the idea of training an engine without any parallel data to begin with (as opposed to supervised learning where you do have data). In theory, we have no bilingual data, but in practice there’s often some seed data like a bilingual dictionary. After that, there are approaches such as cross lingual word embeddings and adversarial training. These are used to “initialise” the MT engine, and then training cycles iterate to optimise the performance against some objective function like a language model score. That iteration stops once you are happy with the performance.
There’s been a lot of research on this particular topic so if you’re interested in reading more, check out issue #28 (Hybrid Unsupervised Machine Translation) of the blog which actually links to quite a number of papers taking different approaches.
4) Domain Adaptation
The concept here is that rather than having separate engines for different domains or content types, to train on all of the data that we have across domains, and then somehow adapt on the fly to the input. This is particularly important because NMT engines are not great at generalising with things they haven’t seen before. So if we have a legal engine, it’s really not going to do well on pharmaceutical content.
Domain adaptation is another topic that’s run the full gamut of the blog starting at issue #9 (Domain Adaptation for Neural MT) and continuing to issue #71 (Knowledge Distillation for Neural Machine Translation). The basic, standard approach for domain adaptation in Neural MT is partially training a larger model on generic data to a certain point, and then finishing the training with in-domain data, essentially to tune the parameters towards that data at the end.
One particular approach based on this idea that has worked very well has been on-the-fly adaptation of the dynamic hyper-parameter settings in a neural model. Essentially, our NMT model is trained on data from multiple domains, and then for each input we want to translate, similar sentences in the training data are identified using information retrieval techniques, and then the model parameters are temporarily updated to suit that, carry out the translation, and then reset ready for the next input.
There are, of course, overheads with this approach in terms of computation. But we have found in practice that it works really well, particularly when the multiple domains have some similarity - perhaps on a lexical level - but ultimately are distinct enough.
5) Evaluation
Are existing automated metrics such as BLEU and TER still effective with Neural MT? We all know that they have been largely criticised in the MT community, despite being the de facto standards. However, it seems that these metrics may even be less effective for NMT. There has been some work on different types of metrics that are more suitable for NMT, such as character based ones. But for now, the old favourites are still very much in circulation. In issue #90 (Tangled up in BLEU: Reevaluating how we evaluate automatic metrics in MT) we looked at a paper that was exploring alternatives to these traditional automatic metrics. We have also explored other metrics, such as the new kid on the block, YiSi (#87 - A Unified Semantic MT Quality Evaluation and Estimation System). Issue #92 (The importance of references in evaluating MT output) explored how references play a significant role in MT evaluation, and just last week, issue #99 (Training Neural Machine Translation with Semantic Similarity) explored another metric that makes use of semantic similarity for Machine Translation evaluation.
More to the point, now that we undoubtedly have better MT output, how do we run better evaluations to help avoid, perhaps, exaggerated claims? The topic of “human parity” for machine translation caused a lot of waves and there has been extensive work recently on how to design and implement rigorous evaluation setups. A recent paper by a number of leading researchers on the topic set out 5 recommendations in this regard ranging from the assessors themselves to the test sets, and methodology. The recent issues #80 (Evaluating Human Parity in Machine Translation) and #81 (Evaluating Human Parity in Machine Translation: Part 2) cover this paper in a 2-part post - one from our own team summarising the work, and then a guest post from one of the authors themselves.
Other topics covered
1) Language modelling
This is the idea of using monolingual target side information in order to inform the translation process. For example, if we’re translating into English, we might have a massive model representing the English language which is in some way used by the translation model’s algorithm to help it decide what the best translation is. At the beginning, these were not widely considered for supervised Neural MT. But then came the idea of BERT - or Bidirectional Encoder Representations from Transformers - which are language models that look at both left to right, and right to left context (hence the bidirectional). Such models, especially when pre-trained and having broad coverage, are very popular and have shown impressive results across many NLP tasks, but researchers are still continuing to explore how these can be effectively incorporated into NMT models. Take a look at issues #68 (Incorporating BERT in Neural MT) and #70 (Sequence-to-sequence Pre-training for Neural MT) of the blog for more detail on this one.2) Robustness
Broadly speaking, the idea here is reducing certain types of errors that seem to be specific to Neural MT. For example, “undergeneration” which is basically missing chunks of translation in the output. You may also have seen examples of “overgeneration” where the decoder essentially gets stuck in a loop and repeats the same word or phrase many times over in the output.
The first step to resolving these types of issues is understanding exactly why they’re happening, and in many cases the answer is noisy training data. Making sure the training data is as clean as possible is crucial. Other lines of research have included so-called “copying” or identifying certain entities in the source that, rather than actually going through the translation model itself, should be effectively copy/pasted into the translation output.
Lastly, it was identified that a number of issues were systematic in nature, though not necessarily easy to detect, and thus would be good candidates to be fixed automatically as a post process - so-called Neural Automated Post-Editing. Again, check out issues #10 (Evaluating Neural MT post-editing) and #35 (Text Repair Model for Neural Machine Translation) for more on this topic.
3) Speed and scaling
This is relatively self-explanatory - we want both training to be faster and translation to be faster. How is this achieved? Going back to the very first post we published in our blog series, one approach is to make better use of the hardware at our disposal. Effectively, we’re repurposing hardware that has been optimised for one task (i.e. Graphics processing) for another task and thus we are still exploring the best ways in which to do this. Check out issue #1, for example, for more information on things like half-precision floating-points!
The other point is related to improving the efficiency of the algorithms themselves, such as optimising the beam search, or pruning the search space - both topics which were relevant for SMT. Additionally, there has been work on the idea of “control networks” which try to more efficiently use large models without sacrificing quality (as opposed to using smaller, but faster models). You can find more informations on this in issues #17 (Speeding up Neural MT) and #72 (Computation versus Quality for Neural MT) of the blog.
Summary
Looking back, there are certain trends and topics that keep resurfacing. These are the key areas where Neural MT researchers and developers are focussing their efforts and we at Iconic also keep actively researching, so that our tailored engines include the latest advances in the field. The topics we covered above will surely keep reappearing in our blog series as we try to find answers to still unsolved questions such as:- What are the latest advances in the field?
- What do we do for languages or use cases where we don’t have a lot of data?
- How do we effectively handle specific terminology, or translate unseen words?
- How can we tell exactly which words translated as which so that we can put back tags?
- Can we incorporate monolingual information to validate the output, like language models?
- How do we make the engines more flexible for different types of content?
- And how do we properly evaluate the output?
Tags:
Language Weaver
Author
Dr. Carla Parra Escartín
Global Program Manager