
Introduction
It is known that neural machine translation (NMT) is particularly tricky in the case of low-resource languages. Thus, it is not surprising that researchers are actively investigating how to improve the performance on NMT systems for low-resource languages and many approaches are currently being explored. In issue #88 we reviewed a method to use pre-trained models, i.e. auto-encoders trained to re-construct texts from deliberately corrupted texts, for multilingual NMT. We also reviewed an unsupervised parallel sentence extraction method for NMT in issue #94. Another approach that has shown good results in the past is to take advantage of closely related languages. In this way, a low-resource language pair can benefit from high-resource language pairs Neubig and Hu (2018). In this post, we review a method proposed by Wang and Neubig (2019), to further improve the performance by selecting proper data “from other auxiliary languages” for NMT training.
Target Conditioned Sampling
Wang and Neubig (2019) expands the work done by Neubig and Hu (2018), which tried to leverage data from closely related languages. The idea of the "Target Conditioned Sampling" (TCS) algorithm is to select sentence pairs directly from auxiliary languages, rather than using the data from one closely related language or the whole corpus of many languages. The resulting NMT system of a low-resource language pair is trained by adapting an NMT system built with selected data, as described in Neubig and Hu (2018). The TCS algorithm determines which new source-target sentence pairs from other languages could be added to the training data. It works as follows:
- Choose a target sentence y from “the union of al2l extra data”, based on a distribution Q(Y), which is uniform distribution in the experiment.
- Gather all (x_i, y) pairs, given the selected sentence y, and calculate their similarity sim(x_i, s), which is the probability that x_i is a sentence in source sentences s.
- Select an x_i to form a pair (x_i, y) based on Q(X|y), which is the probability of a source sentence x that is likely to be a translation of the target sentence y.
Experiments and Results
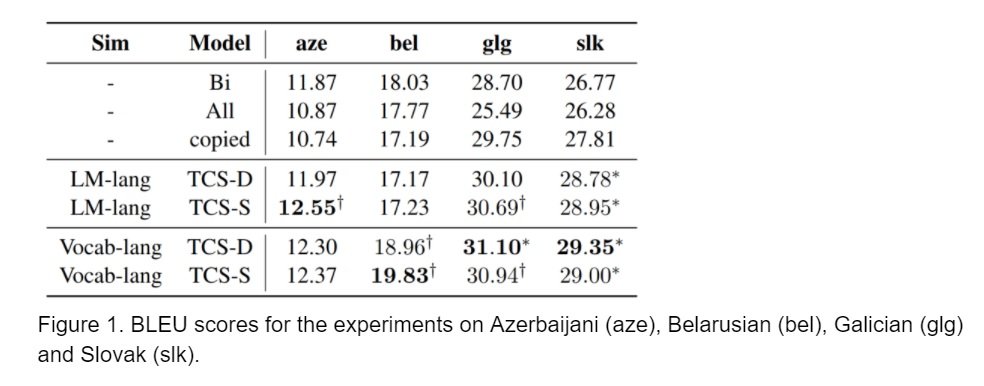
In summary
In this post we reviewed the target conditioned sampling (TCS) algorithm to optimise data selection for multilingual NMT. The approach is an extension to the work by Neubig and Hu (2018), where performance of low-resource NMT is improved by taking advantage of pre-trained models of “related” higher-resource languages. The idea is that we break the corpora into units of sentence pairs and consider which of them are to be used for training. The results showed that it can further improve the performance given the same resources used for training.
There are some aspects we could look into to improve the approach. Q(Y) can definitely be replaced with a distribution that considers the similarities among target sentences. A possible combination of similarities on both language level and sentence level might be interesting. Different similarity measures might also help improve the results. Lastly, it would be great to see the results on more language pairs, and it will be very interesting to see an analysis (and evidence) that shows sentence pairs selected from lesser-related languages also help low-resource NMT.