Issue #131 - Measuring and Increasing Context Usage in Context-Aware NMT


Introduction
Context-aware neural machine translation (NMT) is a topic which has often been covered in this blog, for its application to domain adaptation or document-level NMT (see issues #15, #31, #34, #39, #98, #128). However, most papers on context-aware NMT present approaches which have the ability to leverage context information, but they don’t measure how much of this information they actually use at translation time. Today we take a look at a paper by Fernandes et al. (2021) which introduces a metric to quantify the usage of context by context-aware MT models. It also proposes a simple method to increase this usage. According to the experiment results, the increased usage of context improves automated metrics such as BLEU or COMET, as well as performance on anaphoric pronoun resolution and lexical cohesion contrastive datasets.
Measuring Context Usage
Fernandes et al. propose a new metric, conditional cross-mutual information (CXMI), to measure quantitatively how much context-aware MT models actually use the available context. This metric compares the model distributions over a dataset with and without context. It is inspired from mutual information, which can be expressed as the difference H(Y)-H(Y|X) between the entropy H(Y) of the target Y and the conditional entropy H(Y|X) of Y given the source X. CXMI is the difference HqMT(Y|X)−HqMT,C(Y|X,C) between the entropy of an MT model qMT used without context, and the entropy of the same model used with context. Thus this metric is measuring how much information the context C provides about the target Y given the source X. It applies to any probabilistic context-aware MT model.
Experiments were performed with document-level translation tasks by training Transformer models on two language pairs (English-German and English-French) on the IWSLT corpus. To check that the findings are not conditioned to small datasets, other models were trained on a pre-training set consisting of the filtered ParaCrawl corpus, and fine-tuned on IWSLT. During training and translation, the context is simply concatenated to the source sentence. Also during training, the number of source and target sentences used as context varies randomly from 1 to 4 to ensure that the model is able to translate with different context sizes in that interval.
CXMI values were computed for two models: one with source context of size 1 to 4, and one with target context of size 1 to 4. The findings are that a source or target context of one or two sentences is effectively used by the model, and that target context is used slightly more than source context. With more distant context (size 3 or 4), the usage plateaus or even decreases.
Increasing Context Usage
In order to boost the context usage, particularly with respect to more distant contexts, the authors propose a technique they name “Context-aware word dropout”, which consists of applying word dropout on the current source sentence, but not on the context. Word dropout is a commonly used regularization technique to avoid overfitting. It is achieved by dropping tokens and replacing them with a mask token given a dropout probability p. The intuition behind applying word dropout on the current source sentence but not on the context, is that it encourages the model to use the context to compensate for the missing information in the current source sentence.
The impact of context-aware word dropout on target-side context usage was measured by calculating CXMI with several values of the dropout probability p. As shown in the following figure, the result is a steady increase of the CXMI value when p is increased. Interestingly, with higher values of p, and especially for p=0.3, the increase of CXMI for more distant contexts is also higher. 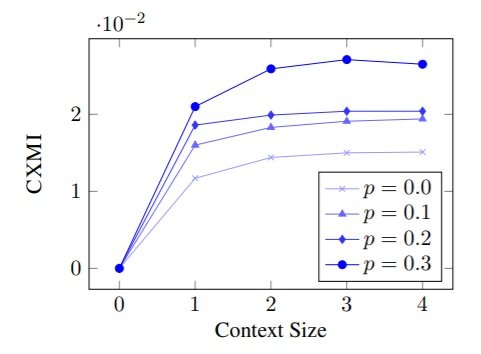 The ability of the models to capture context and the impact of context-aware word dropout was evaluated on translation quality with BLEU and COMET automated metrics, as well as on two contrastive datasets targeting anaphoric pronoun resolution and lexical cohesion. These experiments were performed comparing models trained with a fixed-sized context: a baseline that has no context, a model having as context the previous target sentence, and a model having as context the previous target and source sentences. Each model is trained with different values of p: 0, 0.1 and 0.2. When decoding, the previous sentence gold reference was used as target context.
The ability of the models to capture context and the impact of context-aware word dropout was evaluated on translation quality with BLEU and COMET automated metrics, as well as on two contrastive datasets targeting anaphoric pronoun resolution and lexical cohesion. These experiments were performed comparing models trained with a fixed-sized context: a baseline that has no context, a model having as context the previous target sentence, and a model having as context the previous target and source sentences. Each model is trained with different values of p: 0, 0.1 and 0.2. When decoding, the previous sentence gold reference was used as target context.
The MT quality results in the non-pretrained model show that positive values of p consistently improve the performance of the models with context compared to models running with p = 0, as well as with the sentence-level baseline with the same values of p. Improvements for the pretrained model are smaller but models trained with context-aware dropout still always outperform models trained without it. Regarding the evaluation on contrastive datasets, increasing the context-aware dropout leads in general to improved performance, particularly for the non-pre-trained model.
In summary
The paper by Fernandes et al. (2021) presents a metric to measure the context usage in context-aware MT models. This metric applies for any probabilistic context-aware machine translation model. With this metric, the authors find that a source or target context of one or two sentences is effectively used by the model, and that target context is used slightly more than source context. The paper also introduces a simple way to increase the context usage: by applying word dropout to the current source sentence but not to the context, the context plays a more important role. The MT quality, according to BLEU and COMET, as well as the performance on anaphoric pronoun resolution and lexical cohesion, improves when the context usage is increased.Dr. Patrik Lambert
All from Dr. Patrik Lambert
Related Articles
