
Modeling Bilingual Conversational Characteristics for Neural Chat Translation
Introduction
For the first time in this blog series, we look at work on translating conversational text, which is particularly challenging for neural machine translation (NMT). Its current state fails to capture the dialogue history of conversational text translation. This leads to role-irrelevant, incoherent and inconsistent translations. While context-aware NMT (see our most recent posts on the subject #83, #98, #128 and #139, as well as earlier ones) can be used to try and capture the dialogue history; it may struggle if it doesn’t explicitly model the characteristics inherent to conversational genre, such as role preference, coherence and consistency. In today’s blog we look at research by Liang et al., 2021 who propose using latent variables to capture the distributions of these conversational characteristics and incorporate them into the NMT model to improve the translation quality.
The Problem
In a conversation, the dialogue history contains valuable information pertaining to:
- the role each user plays, in terms of their style, lexical preferences, emotion,
- coherence, whereby the utterances of each participant logically connect to the previous,
- lexical consistency, as the particular lexical choice or terminology in that chat.
Without these, the translation may be adequate at a sentence level, but will be abrupt, not capture the conversational flow and risk not making sense. Context-aware NMT will go some way towards addressing these issues, however it will not automatically know which aspects to focus on.
Chat model
Conditional Variational Auto-Encoders (CVAEs) have been used in the past to learn distributions which can model similar characteristics. So Liang et al, 2021 experiment with learning latent variables via CVAE to specifically capture and integrate them via modules in the NMT architecture: their proposed model is named CPCC as it Captures role Preference, Coherence and Consistency. It includes 3 specific latent variational modules which learn distributions of:
- Role preference: via a role-tailored latent variable, sampled from distributions conditioned on utterances from the specific role, previous role-specific source language turns,
- Dialogue coherence: A coherence latent variable, generated by a distribution conditioned on the source language dialogue history, using source-language turns to maintain coherence,
- Translation consistency: A latent variable modelling consistency by the distribution conditioned on the paired bilingual conversational utterances, to encourage translation consistency.
These different types of context are then integrated into the proposed Variational NMT model (combining CVAE and NMT), which introduces latent variable z into the NMT conditional distribution. Given a source sentence X, a latent variable z is sampled by the prior network from the encoder. In this case we have 3 flavours of z, reflecting the aforementioned bilingual chat characteristics. The target sentence is generated by the decoder, incorporating the parameters of the posterior network and Kullback-Leibler divergence between the distributions produced by prior network over posterior network (detailed algorithms in paper).
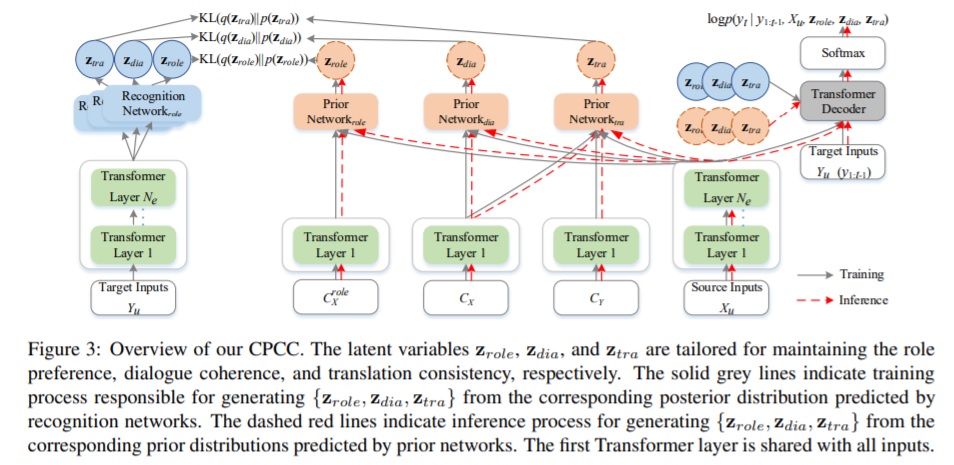
The figure below, taken from the paper, illustrates the following model components:
- Input representation: in addition to the usual word embeddings, they incorporate role and dialogue turn embeddings, with an aim of modeling both dialogue and translation simultaneously. Each input utterance is projected into the embeddings, and unified into a single input via a sum operation.
- Encoder: prior and recognition networks are trained, integrating representations of the source input (Xu) by applying mean pooling with mask. For context inputs (CXrole,CX,CY) in diagram below) the first encoder layer is shared.
- Latent variational modules to capture the latent variables described above. These learn the distributions for the relevant characteristics: at training the posterior distribution conditions on role-specific utterances/source-language utterances/paired bilingual dialogue utterances, combined with the current translation. This results in prior distributions representing each of Zrole, Zdialogue, Ztranslation.
- Decoder-which incorporates these 3 latent variable modules either from the predicted posterior distribution at training or from the prior distribution at inference. These are fed into the decoder via a projection layer followed by linear transformation.
- Training objectives: the model is first trained on large-scale sentence level data, to minimize the cross entropy objective. It is then fine tuned on chat translation data, incorporating KL divergence of posterior over prior distributions for the latent variables (detailed algorithm in paper).
Datasets: Initial training is on WMT data, before finetuning on chat datasets:
- BConTrasT: dataset from WMT 2020 Chat Translation Task, for English-German (comprising 550 dialogues, 6,216/7,629k utterances, details in paper)
- BMELD dialogue dataset which authors constructed for Chinese- English (comprising 1036 dialogues, 4,427/5,560k utterances). Based on the English MELD dataset, they crawled corresponding Chinese translations which were post-edited by students.
Results
In evaluating how well these characteristics are addressed they measure coherence automatically by cosine similarity, and on that basis show a slight increase. Human evaluation indicates an improvement over various baselines in all 3 categories (role, coherence, consistency), see table below, where ‘FT’ signifies finetuning on chat data. The 3 models in the middle are context-aware NMT models, indicating that the CPCC does indeed capture characteristics valuable to the translation of conversational data which may not be captured even by context-aware models. ‘Pref’ indicates role preference, ‘Coh’ coherence, ‘Con’ consistency, and ‘Flu’ fluency.
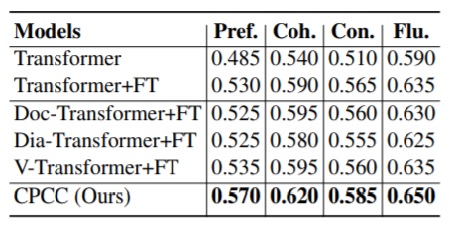
The authors carried out ablation studies which indicated that all 3 modules were important to the process. Automatic evaluation indicated that the model improved over the various baselines on both datasets. However, given that the BLEU score for the Transformer+FT (which is sentence based and does not capture context) was higher than some context-aware models, it is unclear whether the automatic metrics are useful.
In summary
Liang et al (2021) integrate latent variables into the NMT model, capturing bilingual chat characteristics, in order to induce role-specific, coherent, and consistent translations. They do so by adapting Variational NMT, with human evaluation indicating that they have improved not only over the baseline, but also over context-based NMT models.

Author
Dr. Karin Sim
Machine Translation Scientist