
Do Context-Aware Translation Models Pay the Right Attention?
Previous blogs have covered various aspects of context-aware neural machine translation (NMT), from incorporating context (monolingually in #61), the architectural adaptations for incorporating context ( #83 and #98), to metrics for evaluating how well it is being included (#131). In today’s post we look at work by Yin et al., 2021 which considers the context that human translators require when disambiguating, and whether NMT models pay attention to the same context.
The problem
While we have recently seen progress towards developing context-aware NMT models which consider the surrounding sentences (instead of merely sentence-by-sentence ones), many seemingly fail to fully utilise the extended context they have access to. This results in incorrect disambiguation of pronouns or polysemous words, as is illustrated below where a context-aware baseline model (middle example) uses the wrong pronoun in the final sentence:

The amount of attention which the context-aware model gives to items in the context window is highlighted in relevant shades, indicating that while the attention is on the wrong items in the middle example, the model with regularization on attention manages to correctly resolve the pronoun (in the example at the bottom).
Datasets and annotation
In order to investigate what context is necessary for disambiguation, and whether the models are paying attention to correct context, the authors create a dataset they call SCAT (Supporting Context for Ambiguous Translations). It comprises 14k annotations from 20 professional translators indicating what context they found useful in disambiguating French translation options for an English source sentence. The tasks were:
- Pronounce Anaphora Resolution (PAR), where the translators chose the correct French gendered pronoun associated with a neutral English pronoun
- Word Sense Disambiguation (WSD), where the translators picked a correct version of a polysemous word
For the PAR task, they used the contrastive test set compiled by Lopes et al., 2020, comprising 14k examples from the OpenSubtitles2018 dataset. Due to lack of data for the WSD task, they automatically generated some from the same data, identifying polysemous English words and possible multiple French translations (such as ‘clou’ or ‘ongle’ for the English word ‘nail’). Using word alignments they determine which pairs are semantically and grammatically similar in context, filter the tuples using an entropy threshold, extract sentence pairs containing an ambiguous word pair, and replace the French word with one from the same group. Annotators had to select the correct out of 2 translations, and highlight the requisite context. Annotator agreement for the datasets was high, at Fleiss Kappa 0.82 and 0.72 respectively. The authors acknowledge that with automatically generated data there is a risk of misalignments, which may have meant that some examples don’t give useful context, for example. This may be the reason why the context for WSD appeared not to be so relevant. The fact that the task of selecting a translation in context differs from actually translating it likely explains the reason they selected more target context for disambiguation.
Do models pay the right attention?
They then compare the attention distribution of context-aware models to the context highlighted by the human annotations, and measure the alignment between them. For this they used a base transformer where the previous 5 source and target sentences were incorporated by prepending and separating from the current sentence with a tag. To calculate the similarity between the model attention for the ambiguous pronoun and the highlighted context they constructed a vector tracking which tokens were marked by human annotators. They then compared this to the models' attention using 3 metrics: dot product, KL divergence, and probes needed to find the correct token (after ranking the tokens according to model attention). They computed the similarity over 1000 SCAT samples, this is displayed in the column ‘baseline’ of table below (Table 5). They found that there was a relatively high alignment between encoder self attention and SCAT, but very low alignment between SCAT and decoder attention.

Regularizing attention
On the basis that nudging the model’s attention towards words that humans use for disambiguation may improve the translation quality, the authors attempt to regularize the attention to increase alignment to that of the supporting context evidenced in SCAT. They do so by appending the attention regularization loss to the regular translation loss. In addition to the aforementioned baseline with the prepended concatenated context, they train 2 other models with attention regularization:
- Attnref-rand: jointly train on MT objective and regularize on a randomly initialised model
- Attnreg-pre: pretrain on MT objective then jointly train on it with regularized attention
From the results in Table 5 we can see the dot product alignment between SCAT and attention in the decoder has increased with attention regularization, hopefully resulting in more useful context.
Results and evaluation
For evaluation, besides automatic evaluation which is unsuitable for capturing discourse phenomena, they use:
- mean F-measure on translation of ambiguous pronouns in 4,015 remaining examples from dataset (Lopes et al., 2020)
- contrastive testset (Bawden et al., 2018) with 200 PAR examples and 200 WSD examples
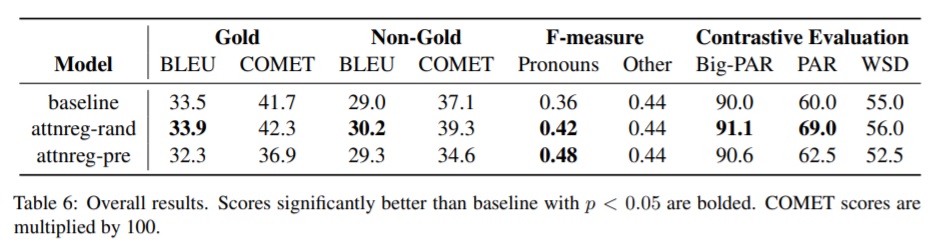
As can be seen from the results (above), Attnref-rand improves on all metrics, proving the effectiveness of attention regularization. Attnref-pre leads to significant gains in word F-measure for ambiguous pronouns, increasing F-measure from 0.36 to 0.48. Attnref-pre generally has better alignment which may suggest that attention regularization works best after initial training.
In summary
Yin et al. find that even context-aware NMT models are currently unable to fully leverage the disambiguating context, when compared with that which is selected by human translators. With attention regularization (nudging the attention of the model towards the human-annotated disambiguating context) they can, however, be encouraged to do so. This is effective in improving the translation of ambiguous pronouns, currently a real problem in MT.

Author
Dr. Karin Sim
Machine Translation Scientist