
Introduction
The pursuit of finding a way to evaluate Machine Translation (MT) accurately has resulted in a vast number of publications over the years. This is indicative of the difficulty of the task. Researchers keep searching for the magic formula that can accurately depict if MT output is good or bad. At Iconic, we are also very interested in evaluating our engines accurately, and that is reflected in the number of publications around MT evaluation that we have written about in this blog series. We revisited some of this in our #100 post, but since then we have had other posts on MT evaluation, like #104, #106 and the most recent one, #109, which looked at one of the top papers on MT evaluation metrics at WMT 2020.
In today’s post we will look at the work done by Avramidis et al. (2019) to create a Test Suite for evaluating German into English Machine Translation. Their work builds upon a previous publication by Burchardt et al. (2017), and their approach was used to analyse MT systems submitted to this year’s WMT translation task in Avramidis et al. (2020). If you read our blog weekly, this topic will sound familiar, as we covered the proposal by Isabelle et al. (2017) to create Test Suites for MT evaluation in our post #104. Burchardt et al. (2017) and Avramidis et al. (2019) actually constitute an example of how a Test Suite can be built to linguistically evaluate MT in a semi-automated manner.
The method
Developing a Test Suite is not a trivial task, and the authors follow an iterative approach comprising 5 main steps, which is illustrated in Figure 1. Prior to the development of the Test Suite, the authors selected 14 linguistic categories and linguistic phenomena associated with each one of them to be tested (a list of all phenomena is included in the appendix of their paper):
- Ambiguity (2)
- Composition (2)
- Coordination and Ellipsis (4)
- False Friends (0)
- Function Word (3)
- LDD and Interrogatives (8)
- Multiword Expressions (4)
- Named Entity and Terminology (5)
- Negation (0)
- Non-verbal agreement (3)
- Punctuation (2)
- Subordination (9)
- Verb/Tense/Aspect/Mood (59)
- Verb valency (4)
Once that is set, the test suite is compiled by manually selecting or handcrafting test sentences in the source language, aiming at testing each phenomenon. The authors report having collected a total of 5,560 sentences. Depending on the linguistic phenomenon being tested, the amount of test sentences ranges between 20 and 180.
To gather sample translations, the authors then use generic publicly available engines and gather translations of all the test sentences. These translations are then validated by an annotator that also writes regular expressions to determine, for each particular phenomenon, if the translation provided is correct or not. At this stage, an initial version of the test suite can be considered ready to be put to the test! To do so, translations from different MT engines are retrieved, and subsequently analysed automatically against the regular expressions already created in the previous step. In those cases where the translation could not be matched, the system will issue a warning, so that an annotator can validate the translation and add it to the test suite. 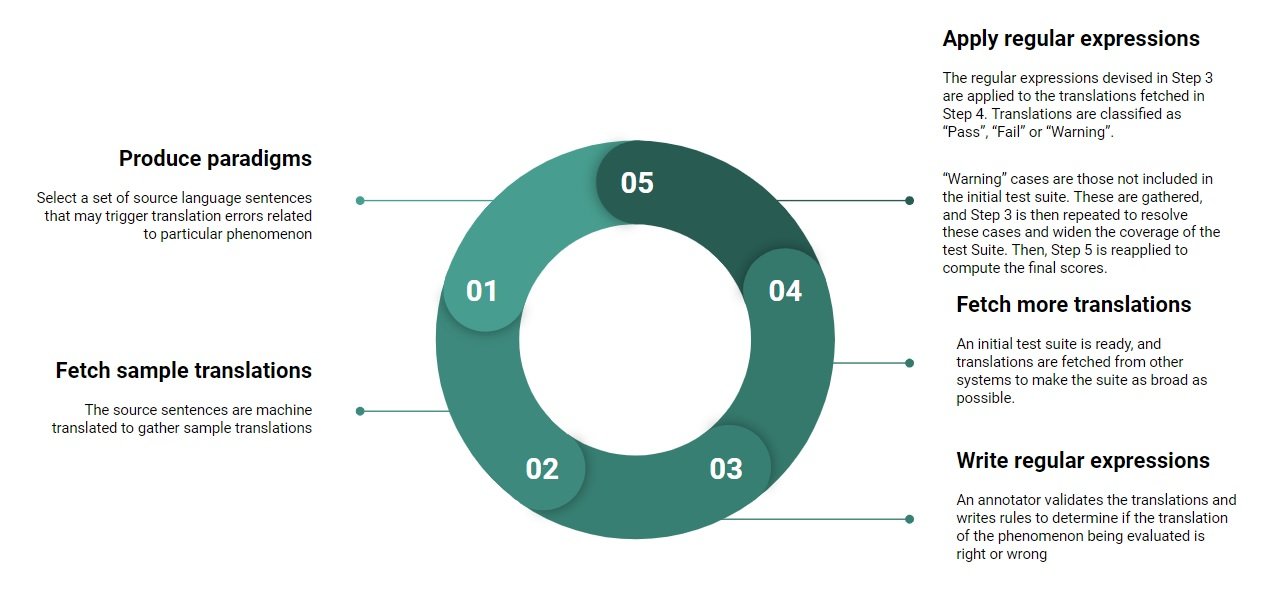
Figure 1: The iterative approach used by the authors to develop their Test Suite
As you can see, this iterative process ensures that the test suite is constantly updated whenever new translations are fetched, and over time it will become wider and more accurate. If you are curious to see what the test suite looks like, a subset of 238 sentences is available on GitHub.Their results
The authors use their Test Suite to evaluate the systems submitted to WMT 2019 (Avramidis et al. 2019), and WMT 2020 (Avramidis et al. 2020). The accuracy for any given phenomenon is measured as the number of correct translations divided by the number of all test sentences for that particular phenomenon.
In 2019, 10% of the translations came out with warnings, and a human annotator then spent 70 hours of work to reduce the warnings to 3%. Overall, the systems for WMT 2019 achieved a 75.6% accuracy on average. That is, one out of four test sentences is usually not translated properly. Interestingly, the engines seem to hardly make mistakes in the negation category (80% accuracy), followed by composition, function word, subordination and non-verbal agreements. The lowest performing categories were multiword expressions and verb valency, which had an accuracy of about 66%.
In 2020, warnings were obtained for 10% of the translations as well. This time, the human annotator spent 45 hours validating those warnings, and they were almost entirely resolved (only 1% remained unresolved). Negation was again the category that scored best, with an accuracy of 97.3%. It was followed by composition (85.3%), subordination (85.3%), named entities and terminology (82%). The categories in the lowest range were multiword expressions, ambiguity, false friends and verb valency, with accuracies ranging between 68.9 and 71.5%.
When compared with 2019, the results from 2020 look promising, as it seems Neural MT is getting better. However, and as the authors also rightly point out, these results need to be taken with a pinch of salt: while the test suite is enlarged every year, it doesn’t account for all possible translation errors and hence high scores do not necessarily mean that a particular grammatical phenomenon is always translated accurately, but rather that “the current test items of the test suite are unable to expose difficulties of the systems” (Avramidis et al., 2020). In the 2020 paper, the authors state that BLEU scores obtained for the different systems seem to correlate with the macro-average accuracy obtained using the test suite for all systems except one.
In summary
As we concluded in issue #104, these test suites can be very useful to evaluate MT output in a more systematic way and can complement existing evaluation metrics, but developing them is not a trivial task. The efforts reported by Burchardt et al. (2017) and Avramidis et al. (2019, 2020) for the language pair German>English confirm not only the effort required to develop the test suites, but also to maintain and curate them, as after every translation task new “test cases” may appear and the test suite should be updated accordingly. On the other hand, developing test suites has advantages that should not be overlooked:- The iterative process used to expand the test suite makes it possible to start “small” and grow as time elapses;
- Having a test suite allows MT developers to identify and narrow down possible areas of improvement to focus on; and
- Maintaining a test suite also makes it possible to compare the performance of different engines for a specific language pair.

Author
Dr. Carla Parra Escartín
Global Program Manager