
Introduction
Quality Estimation involves predicting the quality of MT output automatically, without any reference. It is invaluable for MT in the wild, as in practical terms the user wants to know whether or not the MT output they are getting is reliable. In previous blog posts we have already looked at referenceless metrics PRISM (#156), and COMET (#109), in addition to Quality Estimation (QE) specifically (#87 and #160). Today we look at work by Kanojia et al. (2021) which tries to probe how good current QE systems are at detecting serious errors in the MT output.
Evaluating QE systems
Currently the performance of QE systems is measured by how well their scores correlate with human judgements. However, this doesn’t properly evaluate the QE systems as it fails to account for what they miss; in particular what type of errors they fail to detect. For example, negation errors are serious yet rare, so will not be reflected in overall score. This research is an attempt to address that gap by exploring adversarial evaluation of QE systems. They do this by constructing a dataset which contains carefully crafted errors of 2 types: meaning-preserving perturbations (MPPs) and meaning-altering perturbations (MAPs). The expectation is that a strong QE system will assign lower scores to sentences with MAPs than those with MPPs.
The dataset is a subset from WMT2020 Quality Estimation Shared Task on sentence-level prediction, where the goal is to predict the score for each source-target pair. The scores are from professional translators covering high to low resource language pairs. For consistency they choose 5 where English is the target language. To ensure that the perturbations are effective they select high quality sentences. The resulting testset contains the following number of sentences: 1245 Russian-English, 1035 Romanian-English, 766 Estonian-English, 404 Sinhalese-English, 100 Nepalase-English.
Perturbations
Meaning-preserving perturbations (MPPs) are defined as small changes in the target side which should not affect overall meaning. These may affect fluency but not adequacy. Whereas meaning-altering perturbations (MAPs) alter the meaning conveyed, and thus affect adequacy. These are automatically introduced in the MT (with the use of spaCy POS tagger where necessary), and aim to mimic actual MT errors:
Meaning-preserving perturbations (MPPs) in the dataset, with examples given in the table below:
- Removal of Punctuations (MPP1)
- Replacing Punctuations (MPP2)
- Removal of Determiners (MPP3)
- Replacing Determiners (MPP4)
- Change in Word-casing (MPP5/MPP6)

Meaning-altering perturbations (MAPs) in the dataset, with examples given in the table below:
- Removal of Negation Markers (MAP1)
- Removal of Random Content Words (MAP2)
- Duplication of Random Content Words (MAP3)
- Insertion of Random Words (MAP4)
- Replacing Random Content Words (MAP5)
- BERT-based Sentence Replacement (MAP6)
- Replacing Words with Antonyms (MAP7)
- Source Sentence as Target (MAP8)

Whether these perturbations can be effectively created in an automatic manner to mirror real MT errors is as yet unclear: negation errors are very real, and creating them seems less problematic, whereas the given examples of MAP7 and MAP5 less so.
The research considers different QE models:
- 3 flavors of SOTA TransQuest, based on crosslingual transformers using XLM-Roberta-L: MonoTQ, SiameseTQ, MultiTQ
- LSTM-based Predictor-Estimator, OpenKiwi, where the predictor is an RNN trained on parallel data, with output fed to an Estimator trained on QE data
- An unsupervised QE method, SentSim, using similarity scores derived from XLM-Robert-Base
Results
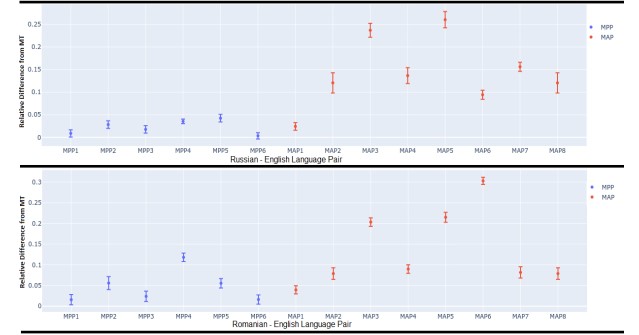
Focusing on MonoTQ as the SOTA QE system, they consider the difference between the average predicted score for the testset before and after perturbations. This is illustrated in the Figure below, displaying the MAP and MPP results for the 2 high resource language pairs (for remainder see paper). Here we can see that on the whole, the sentences with MPPs see a lower drop in score than those with MAPs, which is what you would hope for in a good QE system. The MonoTQ QE system does, however, fail to detect important perturbations such as negation (see MAP1) and, to a lesser extent, antonym errors (see MAP7). It also fails to significantly penalize omission and addition errors, which again are hard to detect and therefore represent valuable issues for a QE system to pick up.
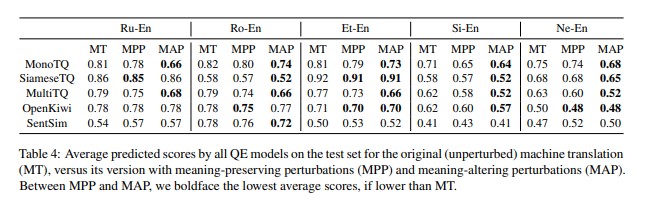
Looking at the scores in the results table below, most models assign lower scores to sentences with MAPs, suggesting that they are somewhat able to detect them. The difference between the scores assigned to sentences containing MPPs and those with MAPs is negligible or non-existent for some models, however. OpenKiwi and SentSim in particular perform poorly.
In summary
This work by Kanojia et al. (2021) introduces a methodology to probe the effectiveness of QE models by injecting perturbations of various types into the data. Strong QE models can largely distinguish between MPPs (Meaning Preserving Perturbations) and MAPs (Meaning Altering Perturbations), and detect at least some of the MAPs. Weaker ones cannot. None perform strongly on categories such as negation omission and antonyms. The methodology is a welcome first step on the way to more thoroughly evaluating the performance of QE systems.

Author
Dr. Karin Sim
Machine Translation Scientist