Introducing Language Weaver Edge 8.7: Smarter AI, secured on your terms


For enterprises and governments around the world, deploying AI is not just about what it can do - it is about efficiency, control, and cost predictability. Language Weaver Edge 8.7 addresses these priorities with two major innovations that bring powerful language AI directly into your infrastructure: Automatic post-editing with Generative Language Pairs and Live speech-to-text transcription.
Language Weaver Edge 8.7 can be deployed in a secure on-premise data center or private cloud, providing enterprise-grade AI with minimal compute demands while keeping you in full control of your models, data, and outcomes.
Generative Language Pairs on-premises: Purpose-built for secure localization
There’s a common belief that to get the best out of AI, you need to run massive models in the cloud. That belief comes from the reality that many teams spend time and money constantly tweaking prompts from huge models just to get the right result. But the truth is, great AI doesn’t have to be heavy or expensive. It just needs to be built by people who deeply understand the problem.
With Language Weaver, automatic post-editing, available with Generative Language Pairs, is now available on-premises – lightweight, easy to deploy, and cost-effective to run. Automatic post-editing, is an AI-driven capability that intelligently identifies and improves translations needing refinement in real-time. This dramatically enhances machine translation quality, increases scalability, and reduces reliance on human intervention.
We combine three AI models to deliver automatic post-editing:
- Translate with auto-adaptive neural machine translation.
- Evaluate with machine translation quality estimation (MTQE).
- Refine with our privately hosted Large Language Model (LLM).
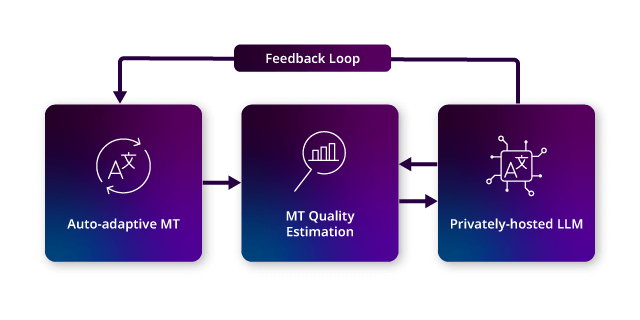
Image showing Language Weaver automatic post-editing with Generative Language Pairs
The process is simple: text is translated, evaluated, and - if rated adequate or poor - refined by the LLM. This evaluate-refine loop can repeat up to three times, using additional context to improve accuracy. Human linguists step in only when needed, and feedback automatically enhances future translations. The result is higher-quality translations with far less manual effort.
Precision over prompts: MTQE that is built for speed and scale
Let’s take a closer look at Machine Translation Quality Estimation (MTQE) -a vital tool for identifying which translations are ready to publish and which need refinement. While some solutions use general-purpose LLMs prompted to review translations, this approach can be resource-intensive and slow, especially when scaled across large volumes of content.
Language Weaver’s MTQE models take a different approach. They are purpose-built AI models trained on hundreds of thousands of human-labeled translation samples by RWS’s in-house linguistic experts. These models are:
- Lightweight and able to run on a single CPU core with just 2GB of RAM
- Fast and scalable, ideal for high-throughput environments
- Reliable and calibrated to assess translation quality sentence by sentence, flagging outputs as good, adequate, or poor
This means you can deploy MTQE across your entire translation pipeline without needing to scale up expensive infrastructure or slow down processes. With Edge 8.7, MTQE can be deployed independently to be combined with your existing Language Pairs (LP), or as part of a Generative LP with automatic post-editing.
Automatic post-editing: Smarter corrections with lower costs
When MTQE flags a translation as needing improvement, our automatic post-editing (APE) engine steps in. Powered by your privately hosted LLM, APE refines translations to improve fluency and correct errors.
What makes this different?
- One LLM engine supports APE across all supported language pairs
- Runs on a single NVIDIA A10 GPU, keeping compute costs low
- Refined through years of research to optimize LLM behaviour per language pair and reduce issues like hallucinations and misinterpreted numbers or entities.
This modular architecture means you can scale your translation capabilities without scaling your infrastructure. In real-world deployments, Language Weaver’s Generative LPs have delivered 77% publishable output across more than 30 million words. If we assumed a $0.10 per word post-edit rate, this is a saving over 2.3 million dollars in post-editing costs.
On-premises transcription AI for secure deployments
Language Weaver Edge already supports on-premises transcription AI (or speech-to-text), giving organizations the ability to transcribe and translate audio securely, quickly, and cost-effectively. By keeping all processing within your infrastructure, you avoid any latency or privacy concerns of cloud-based solutions. Whether it’s for live interviews, internal investigations, or sensitive recordings, Language Weaver Edge ensures fast, accurate insights without compromising control or budget.
Live speech-to-text: real-time transcription for sensitive audio
Edge 8.7 introduces live speech-to-text transcription, enabling users to record, transcribe, and translate audio in real time.
Live speech-to-text is designed for high-sensitivity use cases, including government and military operations, police interviews and investigations, and environments where hands-free interaction is essential – such as fieldwork or accessibility support.
Whether you are transcribing long-form recordings or live conversations, Language Weaver ensures rapid and secure processing entirely within your infrastructure.
Deployment options
Language Weaver Edge offers exceptional flexibility in how speech-to-text AI can be deployed. For scenarios where transcription speed is less critical, such as processing recorded meetings or interviews, CPU-based deployment provides a very low-cost option. For real-time use cases like live captioning or tactical field operations, deploying on a single NVIDIA T4 GPU delivers low-latency performance while keeping infrastructure costs minimal.
This balance of speed and affordability makes Language Weaver Edge ideal for organisations looking to scale transcription AI on their own terms.
Optimized for on-premises: Low footprint with high impact
Language Weaver Edge 8.7 is engineered for cost-effective and high-performance on-premises deployment. Our models are designed to run efficiently on modest hardware.
This means you can deploy advanced AI translation and transcription tools without investing in large-scale infrastructure. Whether you are running in a secure facility or a private cloud, Language Weaver gives you the power to scale intelligently with predictable costs and minimal hardware.
Watch our on-demand webinar, Say hello to Language Weaver Edge 8.7