
MT is considered one of the most difficult problems in the general Artificial Intelligence (AI) and machine learning field.
The so-called AI-complete problems are as difficult to solve as the central artificial intelligence problem itself: making computers as intelligent as people. It is no surprise that humankind has been working to solve the machine translation (MT) problem for almost 70 years now:
We live in a time when there is a proliferation of open-source machine learning and AI-related development platforms. Thus, people believe that given a large amount of data and a few computers, a functional and useful MT system can be developed with a do-it-yourself (DIY) tool kit. However, as many who have tried have found out, the reality is much more complicated, and the path to success is long, winding and sometimes even treacherous.
For an organization to even consider developing an open-source machine translation solution to deployable quality, a few critical elements are required for successful outcomes:
- Basic competence with machine learning technology
- Understanding of the broad range of data needed to build and develop an MT system
- Understanding of proper data preparation and data optimization processes
- Ability to understand, measure and respond to success and failure in model building as an integral part of the development process
- Understanding of the additional support tools and connected data flow infrastructure needed to make MT deployable at enterprise scale
The very large majority of open-source MT efforts fail because they do not consistently produce output that is equal to, or better than, any easily accessed public MT solution or because they cannot be deployed effectively. This is not to say that this is not possible, but the investments and long-term commitment required for success are often underestimated or simply not properly understood.
A case can always be made for private systems that offer greater control and security, even if they are generally less accurate than public MT options. However, in the localization industry we see that if “free” MT solutions that are superior to an LSP-built system are available, translators will use them. We also find that for the few self-developed MT systems that do produce useful output quality, integration issues are often an impediment to deployment at enterprise scale and robustness.
Some say that those who ignore the lessons of history are doomed to repeat errors. Not so long ago, when the Moses SMT toolkits were released, we heard industry leaders clamor “Let a thousand MT systems bloom.” But in retrospect, did more than a handful survive beyond the experimentation phase?
Why is relying on open source difficult for the enterprise?
Both the state-of-the-art of machine translation and the basic MT technology are continuously evolving, so practitioners need to understand and stay current with research to develop viable systems. If public MT can easily outperform home-built systems, there is little incentive for employees and partners to use in-house systems, and thus, we are likely to see rogue behavior from users who reject the in-house system or see users being forced to use sub-standard systems. This is especially true for localization use cases where the highest output quality is demanded.
Producing systems that consistently perform at the required levels demands deep expertise and broad experience. At a minimum, do-it-yourselfers need to have basic expertise in the various elements that surround machine learning technology.
While open sources do indeed provide access to the same algorithms, the essential skill in building MT systems is doing proper data analysis, data preparation and data cleansing to ensure that the algorithms learn from a sound quality foundation. The most skillful developers also understand the unique requirements of different use cases and can develop additional tools and processes to augment and enhance MT-related tasks. Often times the heavy lifting for many use cases is done outside and around the neural MT models.
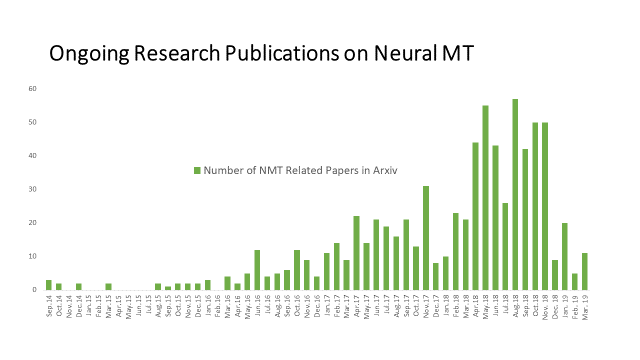
Over the last few years, the understanding of what the “best NMT algorithms” are has changed regularly. A machine translation system that is deployed on an enterprise scale requires an “all in” long-term commitment or it will be doomed to be a failed experiment:
- Building engineering teams that understand what research is most valid and relevant, and then upgrading and refreshing existing systems is a significant, ongoing and long-term investment.
- Keeping up with the evolution in the research community requires constant experimentation and testing that most practitioners will find hard to justify.
- Practitioners must know why and when to change as the technology evolves or risk being stuck with sub-optimal systems.
Open-source initiatives that emerge in academic environments, such as Moses, also face challenges. They often stagnate when the key students that were involved in setting up initial toolkits graduate and are hired away. The key research team may also move on to other research that has more academic stature and potential. These shifting priorities can force DIY MT practitioners to switch toolkits at great expense, both in terms of time and redundant resource expenditures.
To better understand the issue of a basic open-source MT toolkit in the face of enterprise MT capability requirements, consider why an organization would choose to use an enterprise-grade content management system (CMS) to setup a corporate website instead of a tool like WordPress. While both systems could be useful in helping the organization build and deploy a corporate web presence, enterprise CMS systems are likely to offer specialized capabilities that make them much more suitable for enterprise use.
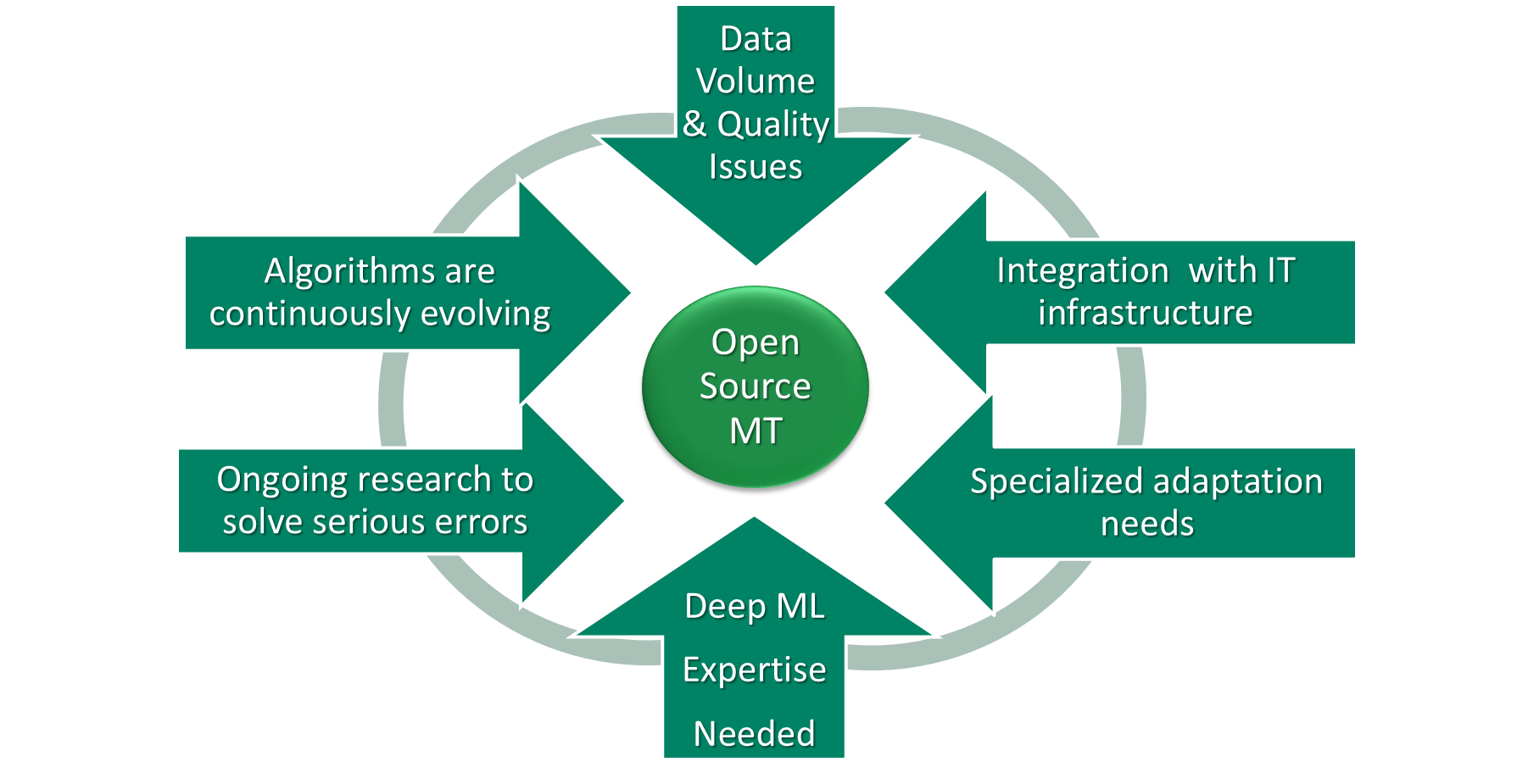
As enterprises better understand the global communication, collaboration and content sharing imperatives of modern digital transformation initiatives, many of them see that MT is now a critical technology building block that enables better DX. However, there are many specialized requirements for MT systems, including data security and confidentiality, adaptation to different business use cases, and the ability to deploy systems in a broad range of enterprise use scenarios.
The issue of enterprise optimization is also an increasingly critical element in selecting such a core technology. MT is increasingly a mission-critical technology for a global business and requires the same care and attention as does the selection of enterprise CMS, email, and database systems.
What are the key requirements for enterprise MT?
There is more to successful MT deployment than simply being able to build an NMT model. A key requirement for successful MT development by the enterprise is long-term experience with machine learning research and technology at industrial scale in the enterprise use context.
With MT, actual business use case experience also matters since it is a technology that requires the combination of computational linguistics, data management, human translator interaction, and systems integration into organizational IT infrastructure for robust solutions to be developed. Best practices evolve from extensive and broad experience that typically takes years to acquire, in addition to success with hundreds, if not thousands, of systems.
The RWS MT engineering team has been a pioneer on data-driven MT technology since its inception with Statistical MT in the early 2000s and has been involved with a broad range of enterprise deployments in the public and private sectors. The deep expertise that RWS has built since then encompasses the combined knowledge gained in all of the following areas:
- Data preparation for training and building MT engines, acquired through the experience of building thousands of engines across many language combinations for various use cases.
- Deep machine learning techniques to assess and understand the most useful and relevant research in the NLP community for the enterprise context.
- Development of tools and architectural infrastructure that allows rapid adoption of research breakthroughs, but still maintains existing capabilities in widely deployed systems.
- Productization of breakthrough research for mission-critical deployability, which is a very different process from typical experimentation.
- Pre- and post-processing infrastructure, tools and specialized capabilities that add value around core MT algorithms and enable systems to perform optimally in enterprise deployment settings.
- Ongoing research to adapt MT research for optimal enterprise use, e.g., using CPUs rather than GPUs to reduce deployment costs, as well as the system cost and footprint.
- Long-term efforts on data collection, cleaning and optimization for rapid integration and testing with new algorithmic ideas that may emerge from the research community.
- Close collaboration with translators and linguists to identify and solve language-specific issues, which enables unique processes to be developed to solve unique problems around closely-related languages.
- Ongoing interaction with translators and informed linguistic feedback on error patterns provide valuable information to drive ongoing improvements in the core technology.
- Development of unique language combinations with very limited data availability (e.g., ZH to DE) by maximizing the impact of available data. Utilization of zero-shot translation (between language pairs the MT system has never seen) produces very low quality systems through its very basic interlingua, but can be augmented and improved by intelligent and informed data supplementation strategies.
- Integration with translation management software and processes to allow richer processing by linguistic support staff.
- Integration with other content management and communication infrastructure to allow pervasive and secure implementation of MT capabilities in all text-rich software infrastructure and analysis tools.
The bottom line
The evidence suggests that embarking on a self-managed open-source-based MT initiative is for the very few who are ready to make the substantial long-term commitment and investments needed. Successful outcomes require investment in building expertise not only in machine learning, but in many other related and connected areas. The same kinds of rules that apply to enterprise decisions on selecting email, content management and database systems should apply here. Properly executed, MT is a critical tool that enhances and expands the digital global footprint of the organization, and it should be treated with the same seriousness dedicated to any major strategic initiative.Tags:
Machine Translation
Author
Kirti Vashee
Independent Language Technology Consultant
Kirti Vashee is an independent language technology Consultant, specializing in machine translation and translation technology. He was also with Asia Online and was previously responsible for the worldwide business development and marketing strategy at statistical MT pioneer Language Weaver, prior to its acquisition by SDL. Kirti has long-term sales and marketing experience in the enterprise software industry, working both at large global companies (EMC, Legato, Dow Jones, Lotus, Chase) and several successful startups